前言
今天给大家介绍的是Python爬取漫画数据,在这里给需要的小伙伴们代码,并且给出一点小心得。
首先是爬取之前应该尽可能伪装成浏览器而不被识别出来是爬虫,基本的是加请求头,但是这样的纯文本数据爬取的人会很多,所以我们需要考虑更换代理IP和随机更换请求头的方式来对漫画数据进行爬取。
在每次进行爬虫代码的编写之前,我们的第一步也是最重要的一步就是分析我们的网页。
通过分析我们发现在爬取过程中速度比较慢,所以我们还可以通过禁用谷歌浏览器图片、JavaScript等方式提升爬虫爬取速度。
开发工具
Python版本: 3.6
相关模块:
requests模块
re模块
time模块
bs4模块
tqdm模块
contextlib模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
文中完整代码及文件,评论留言获取
思路分析
浏览器中打开我们要爬取的页面
按F12进入开发者工具,查看我们想要的漫画数据在哪里
这里我们需要页面数据就可以了


添加代理

漫画下载代码实现
# 下载漫画
for i, url in enumerate(tqdm(chapter_urls)):
print(i,url)
download_header = {
'Referer':url,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
name = chapter_names[i]
# 去掉.
while '.' in name:
name = name.replace('.', '')
chapter_save_dir = os.path.join(save_dir, name)
if name not in os.listdir(save_dir):
os.mkdir(chapter_save_dir)
r = requests.get(url=url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
for j, pic in enumerate(pics):
if len(pic) == 13:
pics[j] = pic + '0'
pics = sorted(pics, key=lambda x: int(x))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for idx, pic in enumerate(pics):
if pic[-1] == '0':
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic[
:-1] + '.jpg'
else:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
pic_name = '%03d.jpg' % (idx + 1)
pic_save_path = os.path.join(chapter_save_dir, pic_name)
print(url)
response = requests.get(url,headers=download_header)
# with closing(requests.get(url, headers=download_header, stream=True)) as response:
# chunk_size = 1024
# content_size = int(response.headers['content-length'])
print(response)
if response.status_code == 200:
with open(pic_save_path, "wb") as file:
# for data in response.iter_content(chunk_size=chunk_size):
file.write(response.content)
else:
print('链接异常')
time.sleep(2)
数据保存

结果展示
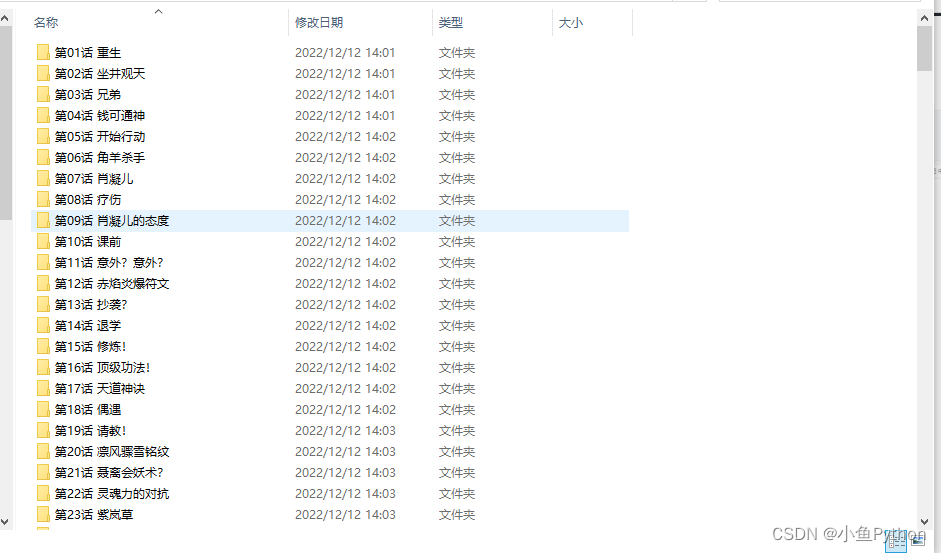

最后
今天的分享到这里就结束了 ,感兴趣的朋友也可以去试试哈
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:Python爬虫实战,requests+tqdm模块,爬取漫画之家漫画数据(附源码) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 