MySQL业务设计


只分享干货、不吹水,让我们一起加油!?
逻辑设计
范式设计
范式概述
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要求,否则,将有很多基本操作在这样的关系模式中实现不了。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF。
第一范式
- 数据库表中的所有字段都只具有单一属性。
- 单一属性的列是由基本数据类型所构成的。
- 设计出来的表都是简单的二维表。
示例

解决办法
name-age列具有两个属性,一个name,一个 age不符合第一范式,把它拆分成两列。

第二范式
要求表中只具有一个业务主键,也就是说符合第二范式的表不能存在非主键列只对部分主键的依赖关系。
示例
有两张表:订单表,产品表
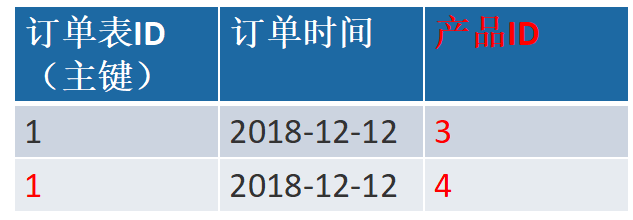
解决办法
一个订单有多个产品,所以订单的主键为【订单ID】和【产品ID】组成的联合主键,这样2个主键不符合第二范式,而且产品ID和订单ID没有强关联,故,把订单表进行拆分为订单表与订单与商品的中间表。
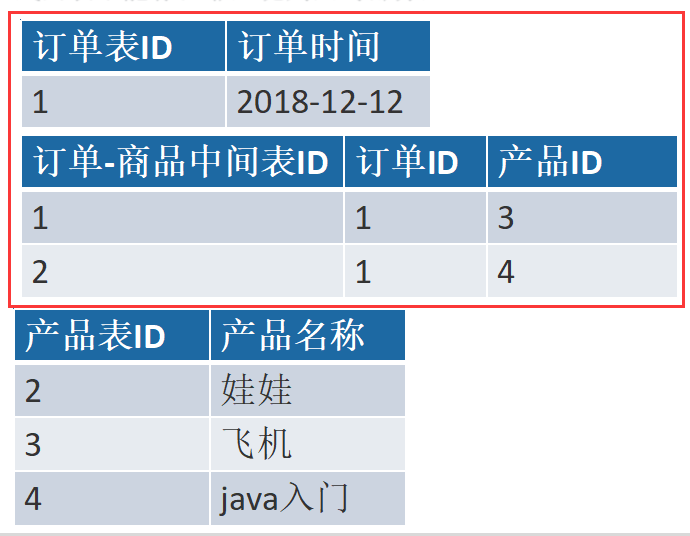
第三范式
指每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。
示例
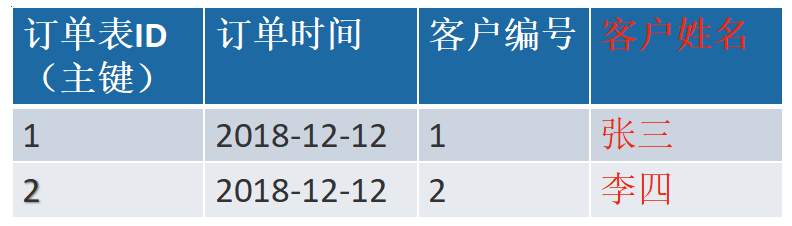
解决办法
其中
客户编号 和订单编号管理 关联
客户姓名 和订单编号管理 关联
客户编号 和 客户姓名 关联
如果客户编号发生改变,用户姓名也会改变,这样不符合第三大范式,应该把客户姓名这一列删除
范式设计实战
按要求设计一个电子商务网站的数据库结构,本网站只销售图书类产品,需要具备以下功能:
- 用户登陆 商品展示 供应商管理
- 用户管理 商品管理 订单销售
用户登陆及用户管理
- 用户必须注册并登陆系统才能进行网上交易,用户名用来作为用户信息的业务主键
- 同一时间一个用户只能在一个地方登陆

只有一个业务主键,一定是符合第二范式,没有属性和业务主键存在传递依赖的关系,符合第三范式。
商品信息

一个商品可以属于多个分类,故,商品名称和分类应该是组合主键,会有大量冗余,不符合第二范式。应该把分类信息单独存放
解决办法
另外再建立一个中间表把分类信息和商品信息进行关联

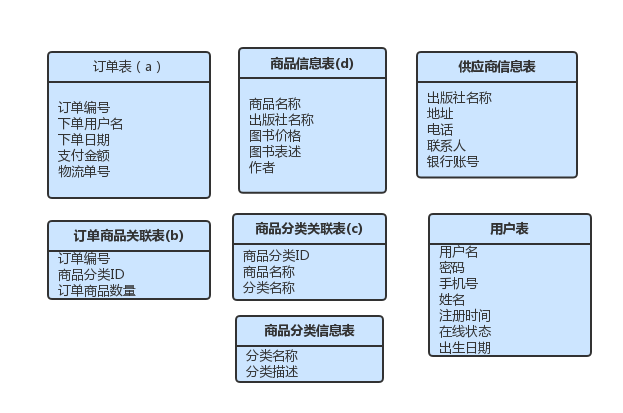
最后的三张表如下

供应商管理功能

符合三大范式,不需要修改,但假如增加新的一列【银行支行】,这样随着银行账户的变化,银行支行也会编号,不符合第三大范式

在线销售功能

有多个业务主键,不符合第二范式,订单商品单价、订单数量、订单金额存在传递依赖关系,不符合第三范式,需要拆解
解决办法
创建一个订单关联表,将商品分类和商品名称拆解出来

这时候,【订单商品分类】与【订单商品名】有依赖关联,故合并如下

表汇总
查询练习
编写SQL查询出每一个用户的订单总金额(用户名,订单总金额)
COPYSELECT a.单用户名, sum(d.商品价格 * b.商品数量)
FROM 订单表 a
JOIN 订单分类关联表 b ON a.订单编号 = b.订单编号
JOIN 商品分类关联表 c ON c.商品分类ID = b.商品分类ID
JOIN 商品信息表 d ON d.商品名称 = c.商品名称
GROUP BY a.下单用户名
编写SQL查询出下单用户和订单详情(订单编号,用户名,手机号,商品名称,商品数量,商品价格)
COPYSELECT a.订单编号, e.用户名, e.手机号, d.商品名称, c.商品数量, d.商品价格
FROM 订单表 a
JOIN 订单分类关联表 b ON a.订单编号 = b.订单编号
JOIN 商品分类关联表 c ON c.商品分类ID = b.商品分类ID
JOIN 商品信息表 d ON d.商品名称 = c.商品名称
JOIN 用户信息表 e ON e.用户名 = a.下单用户
存在的问题
- 大量的表关联非常影响查询的性能
- 完全符合范式化的设计有时并不能得到良好得SQL查询性能
反范式设计
什么叫反范式化设计
- 反范式化是针对范式化而言得,在前面介绍了数据库设计得范式
- 所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反
- 允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间
商品信息反范式设计
下面是范式设计的商品信息表
商品信息和分类信息经常一起查询,所以把分类信息也放到商品表里面,冗余存放。

在线销售功能反范式
下面是在线销售功能的范式设计

首先来看订单表
- 查询订单信息要关联查询到用户表,但用户表的电话是可能改变的,而且查询订单的时候经常查询到用户的电话
- 查询订单经常会查询到订单金额,所以把订单金额也冗余进来
新设计的订单表如下

再来看订单关联表
- 和商品信息反范式设计一样,查询订单的时候经常查询商品分类,所以把商品分类和订单名冗余进来
- 商品的单价可能会编号,如果关联查询查询只能查询到最新的商品价格,而查询不到下订单时候的价格,并且商品单价经常会查询。 所以把订单单价也冗余进来
新设计的商品关联表如下

查询练习
编写SQL查询出每一个用户的订单总金额
COPYSELECT 下单用户名, sum(订单金额)
FROM 订单表
GROUP BY 下单用户名;
编写SQL查询出下单用户和订单详情
COPY
SELECT a.单用户名, sum(d.商品价格 * b.商品数量)
FROM 订单表 a
JOIN 订单分类关联表 b ON a.订单编号 = b.订单编号
JOIN 商品分类关联表 c ON c.商品分类ID = b.商品分类ID
JOIN 商品信息表 d ON d.商品名称 = c.商品名称
GROUP BY a.下单用户名;
总结
不能完全按照范式得要求进行设计,考虑以后如何使用表
范式化设计优缺点
优点
- 可以尽量得减少数据冗余
- 范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化的表更小
缺点
- 对于查询需要对多个表进行关联
- 更难进行索引优化
反范式化设计优缺点
优点
- 可以减少表的关联
- 可以更好的进行索引优化
缺点
- 存在数据冗余及数据维护异常
- 对数据的修改需要更多的成本
物理设计
命名规范
数据库、表、字段的命名要遵守可读性原则
使用大小写来格式化的库对象名字以获得良好的可读性
例如:使用custAddress而不是custaddress来提高可读性。
数据库、表、字段的命名要遵守表意性原则
对象的名字应该能够描述它所表示的对象
例如:对于表,表的名称应该能够体现表中存储的数据内容;对于存储过程存储过程应该能够体现存储过程的功能。
数据库、表、字段的命名要遵守长名原则
尽可能少使用或者不使用缩写
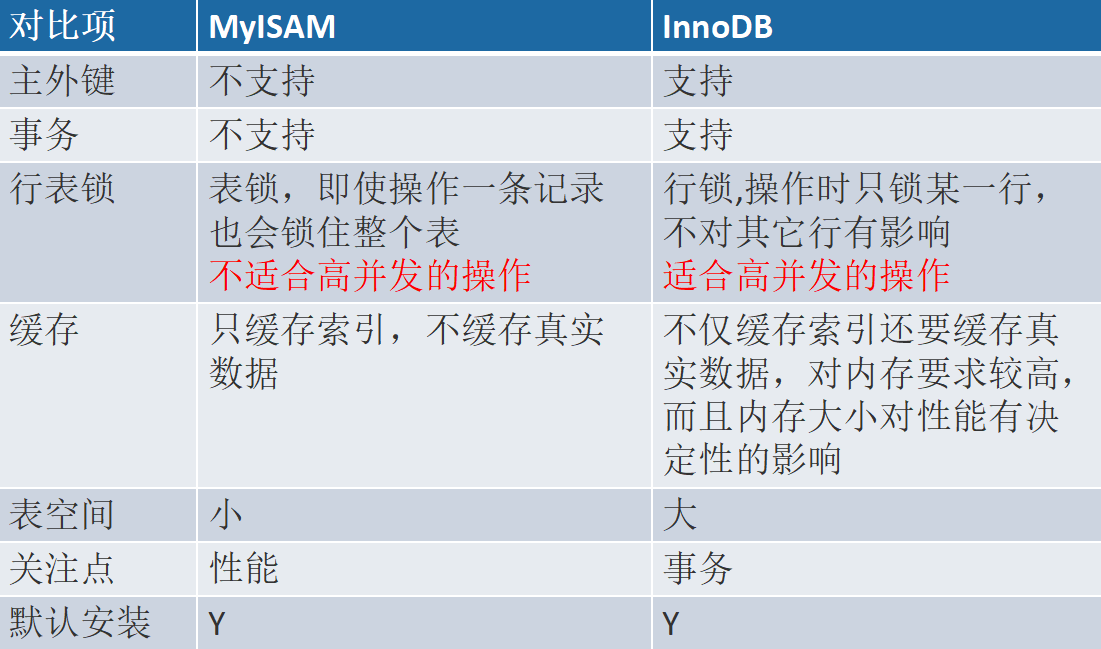
存储引擎选择
数据类型选择
当一个列可以选择多种数据类型时
- 优先考虑数字类型
- 其次是日期、时间类型
- 最后是字符类型
- 对于相同级别的数据类型,应该优先选择占用空间小的数据类型
- 对精度有要求的时候,选择精度高的数据类型。 int<float<double<decimal.
浮点类型

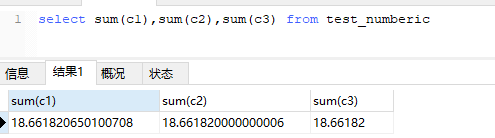
注意float 和double 是非精度类型,如果是和金额相关尽量用decimal

COPYselect sum(c1), sum(c2), sum(c3) from test_numberic;
日期类型
面试经常问道 timestamp 类型 与 datetime区别
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 8 | 1970-01-01 00:00:00/2037 年某时 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
- datetime类型在5.6中字段长度是5个字节
- datetime类型在5.5中字段长度是8个字节
- timestamp 和时区有关,而datetime无关
COPYDROP TABLE IF EXISTS `test_time`;
CREATE TABLE `test_time` (
`c1` datetime(6) NULL DEFAULT NULL,
`c2` timestamp(6) NULL DEFAULT NULL,
`c3` time(6) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
insert into test_time VALUES(NOW(),NOW(),NOW());
COPYmysql> select * from test_time;
+----------------------------+----------------------------+-----------------+
| c1 | c2 | c3 |
+----------------------------+----------------------------+-----------------+
| 2019-12-25 14:44:22.000000 | 2019-12-25 14:44:22.000000 | 14:44:22.000000 |
+----------------------------+----------------------------+-----------------+
1 row in set (0.00 sec)
set time_zone="-10:00"
mysql> select * from test_time;
+----------------------------+----------------------------+-----------------+
| c1 | c2 | c3 |
+----------------------------+----------------------------+-----------------+
| 2019-12-25 14:44:22.000000 | 2019-12-24 20:44:22.000000 | 14:44:22.000000 |
+----------------------------+----------------------------+-----------------+
1 row in set (0.00 sec)
字符串类型
字符串类型所需的存储和值范围
| 类型 | 说明 | N的含义 | 是否有字符集 | 最大长度 |
|---|---|---|---|---|
| CHAR(N) | 定义字符 | 字符 | 是 | 255 |
| VARCHAR(N) | 变长字符 | 字符 | 是 | 16384 |
| BINARY(N) | 定长二进制字节 | 字节 | 否 | 255 |
| VARBINARY(N) | 变长二进制字节 | 字节 | 否 | 16384 |
| TINYBLOB | 二进制大对象 | 字节 | 否 | 256 |
| BLOB | 二进制大对象 | 字节 | 否 | 16K |
| MEDIUMBLOB | 二进制大对象 | 字节 | 否 | 16M |
| LONGBLOB | 二进制大对象 | 字节 | 否 | 4G |
| TINYTEXT | 大对象 | 字节 | 是 | 256 |
| TEXT | 大对象 | 字节 | 是 | 16K |
| MEDUIMBLOB | 大对象 | 字节 | 是 | 16M |
| LONGTEXT | 大对象 | 字节 | 是 | 4G |
定义与变长区别 (CHAR VS VARCHAR)
| 值 | CHAR(4) | 占用空间 | VARHCAR(4) | 占用空间 |
|---|---|---|---|---|
| ‘’ | ‘ ‘ | 4 bytes | ‘’ | 1 bytes |
| ‘ab’ | ‘ab ‘ | 4 bytes | ‘ab’ | 3 bytes |
| ‘abcd’ | ‘abcd’ | 4 bytes | ‘abcd’ | 5 bytes |
| ‘abcdefgh’ | ‘abcd’ | 4 bytes | ‘abcd’ | 5 bytes |
字符串类型相关注意事项
- 在BLOB和TEXT列上创建索引时,必须制定索引前缀的长度
- VARCHAR和VARBINARY必须长度是可选的
- BLOB和TEXT列不能有默认值
- BLOB和TEXT列排序时只使用该列的前max_sort_length个字节
COPYmysql> show variables like 'max_sort_length';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_sort_length | 1024 |
+-----------------+-------+
1 row in set, 1 warning (0.00 sec)
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
原文链接:https://www.cnblogs.com/jiagooushi/p/17358912.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:MySQL用的在溜,不知道业务如何设计也白搭!!! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 