前言
像RCNN,fast RCNN,faster RCNN,这类检测方法都需要先通过一些方法得到候选区域,然后对这些候选区使用高质量的分类器进行分类。这类方法的检测准确率比较高但是计算开销非常大,不利于实时检测和嵌入式等设备。
另一类方法是将提取候选区和进行分类这两个任务融合到一个网络中。既不使用预定义的box也不使用候选区生成网络来进行寻找目标物体。而是通过一些的卷积核来对卷积网络得到的特征来计算类别分数和位置偏差。
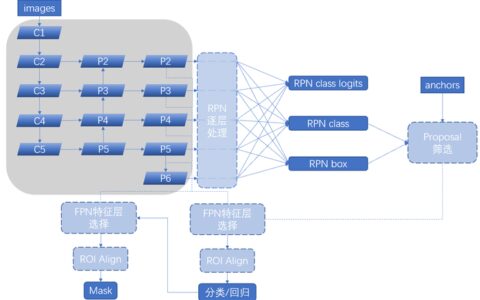
利用卷积神经网络进行区域定位
利用卷积神经网络来进行的分类任务中,通常网络结构最后都有一个全连接层来计算属于各个类别的概率值。例如对于输入为640×480像素的三通道图像,经过多个卷积层池化层以后得到13x18×2048通道的特征图,相当于把原图“划分”(并不严谨)成13×18的小区块(cell)。")
原来的图像由640×480像素压缩到13×18cell,每个cell代表了原图的大范围的区域,我们可以在检测目标物体是否在cell内出现。另外每个cell的信息由2048维的向量表示,因此图像信息并没有丢失太多(除非使用较多的池化层)。
对于每个cell,你可以想象使用1×1卷积层(关于1×1卷积,你可以看这里)来对每个cell进行分类(前景还是后景),同样你也可以连接上其他的卷积层或全连接层来预测Bounding box的坐标:(x,y,w,h),这样你就可以在一个过程中得到类别评分和位置的预测值。
可能有人认为这个过程就是简单的把原图像直接划分为几个网格,这样想就错了。这个过程虽然是用少数的几个cell来代表整张图像,但是cell的特征维度很高,而且cell之间会有一些重叠并非平铺的。在训练的时候,我们还需要对真实的标注和虚拟的cell之间进行一系列的匹配。
如何得到bounding box
可能一开始会让人理解困难的是检测网络是如何将cells物体实际的bounding box,以下是一些使用单步检测策略的目标检测方法:
- SSD:Uses different activation maps (multiple-scales) for prediction of classes and bounding boxes
- YOLO: Uses a single activation map for prediction of classes and bounding boxes
- R-FCN(Region based Fully-Convolution Neural Networks): Like Faster Rcnn (400ms), but faster (170ms) due to less computation per box also it's Fully Convolutional (No FC layer)
使用多尺度有助于实现更高的mAP(mean average precision),能更好的对不同大小的目标进行检测。
这类方法使用的策略总结:
- 训练一个卷积神经网络作为bounding box的回归器和目标物体的分类器。
- 通常,它们的损失函数更复杂,因为它必须实现多个任务(是否存在目标物体、分类、回归)
- 从多个层总结激活结果,然后使用全连接层或特殊的卷积层(工作过程和全连接层类似)来实现分类和确定位置。
- 在预测期间,使用算法例如非极大值抑制来过滤围绕相同对象的多个框。
- 在训练时,使用IoU来表示预测值和真实标签值之间的差距大小。
这类单步检测网络,都会有许多的互相重叠的cell,这些cell有不同的空间位置,尺度,这些cell被称为“anchors”(有时也被称作“priors”,“default boxes”)。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:目标检测之单步检测(Single Shot detectors) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫