1 什么是进程
进程是系统进行资源分配和调度的基本单位,进程表示程序正在执行的过程,是‘活的’,而程序就是一推躺在硬盘上的代码,是‘死的’。
2 进程的调度
1.先来先服务调度算法:对长作业有利,对短作业无利
2.短作业优先调度算法:对短作业有利,对长作业无利
3.时间片轮转法+多级反馈队列
该方法是指,将时间片切成n份,每一份表示一个时间片,这些时间片有一个优先级顺序,最上面的优先执行,一个长任务第一个时间片没有完成会被放到第二个,如果第一个时间片有来任务会优先等第一个执行完在执行第二个。
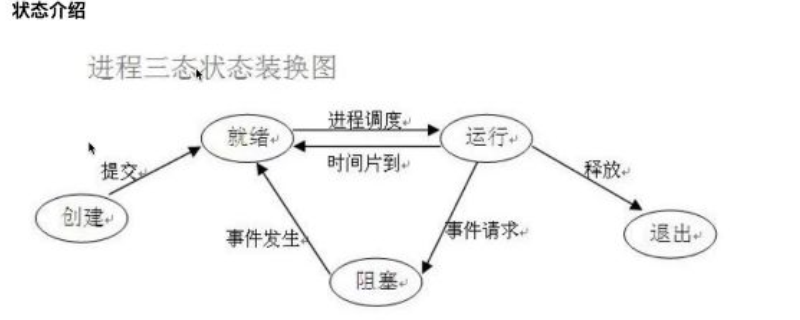
3 进程的三状态图

4. 如何创建进程
4.1 进程创建的第一种方式(掌握)
from multiprocessing import Process # 导入进程模块
import time
# 子进程函数
def func(name):
print('支线%s'% name)
time.sleep(3)
print('over%s'% name)
# windows下创建进程,一定要在main下面创建
# 因为windows创建进程类似于模块导入的方式,会从上往下依次执行,如果放在main外面,会一直创建进程下去
# linux系统中只是将代码拷贝一份,因此不需要在main下面创建
# main表示当该文件是执行文件时才会被运行,该文件是导入的形式时不会被运行
if __name__ == '__main__':
# 1.创建进程对象
# 参数1:需要创建进程的目标函数;
# 参数2:需要给函数传的参数是一个元组形式,当需要传的参数是一个时,注意加一个,
p = Process(target=func,args=('yun',))
# 2.开启进程,告诉操作系统创建进程,操作系统会去申请一个内存空间,把子进程丢进去执行
p.start()
# 3.下面是主进程的执行
print('主')
4.2 创建进程的第二种方式
from multiprocessing import Process
import time
# 1.创建一个类,该类继承Process类
class MyProcess(Process):
# 2.类中子进程的函数名必须是run
def run(self):
print('hello')
time.sleep(1)
print('gun')
if __name__ == '__main__':
# 3.产生类的对象
p = MyProcess()
# 4.开启进程
p.start()
print('主')
总结:
1.创建进程实际上就是在内存中申请了一块内存空间,将代码丢进去运行
2.一个进程产生一个内存空间,多个进程产生多个内存空间
3.进程之间默认是无法进行数据交互的,如果需要交互需要借助第三方模块,在子进程修改全局变量,全局变量不会改变
4.3 进程中join方法
join方法是用来让主进程代码等待调用join的子进程代码运行结束之后,在运行主进程!
p1.join()
p2.join()
p3.join()
print('主')
如果p2和p3不调用join方法,主进程就不会等待其运行结束后再运行!!!
4.4 进程对象和其他方法
一台计算机上面运行着很多进程,那么计算机是如何区分并管理着这些进程,计算机会给这些进程各自分配一个pid
在windows终端,可以通过tasklist命令查看所有的进程pid
tasklist |findstr PID 查看具体进程的命令
在mac电脑,可以通过ps aux查看
ps aux|grep PID 查看具有进程的命令
进程的其他方法:
from multiprocessing import Process,current_process
import time
import os
def func():
# current_process().pid 获取当前进程的进程id
print('%s 正在运行'% current_process().pid)
time.sleep(2)
if __name__ == '__main__':
p = Process(target=func)
p.start()
# os.getpid()也是获取当前进程id的方法
p.terminate() # 杀死当前进程,系统帮您杀死该进程,需要一定的时间,所有下面的is_alive可能为true
print(p.is_alive()) # 判断当前进程是否存活
print('主',os.getpid())
# os.getppid()是获取当前父id的方法
print('主主',os.getppid())
4.5 僵尸进程与孤儿进程
僵尸进程:
当子进程死了,子进程并不会立即占用的进程id号,因为需要让父进程查看到子进程的id、运行时间等信息,所有进程会步入僵尸进程
回收子进程的id号:1,负进程调用join()方法 2.父进程等待子进程运行完毕
孤儿进程:
子进程存活,父进程意外死亡。
操作系统会帮你自动回收子进程的资源
4.6 守护进程
"你死我也不独活" p.daemon = True 方法设置守护进程
from multiprocessing import Process,current_process
import time
def func():
print('奴隶活着')
time.sleep(2)
print('奴隶死去')
if __name__ == '__main__':
p = Process(target=func)
p.daemon = True # 将p这个子进程设置成守护进程,这一句话一定要放在start前面,否则保错
p.start()
print('主人死了')
4.7 进程中的互斥锁
多个进程操作同一个数据的时候,很可能会出现数据错乱的问题
针对上述问题,解决方案就是加锁处理:将并发变成串行,牺牲效率保证数据的安全准确
# 1.导入锁模块
from multiprocessing import Process LOCK
# 2.在主进程中生成一把锁,让所有子进程去抢这把锁,mutex 需要传入对应函数的参数里面
mutex = LOCK()
# 3.在需要加锁的功能上面
mutex.acquire()
# 4.在功能执行完的下面,解锁
mutex.release()
总结:
1.锁不要轻易使用,容易造成锁死的现象
2.锁只在需要争抢数据的时候使用,保证数据的安全
4.8 进程间的通信queue
进程之间是无法相互通信的,因此需要采用第三方模块队列queue。
注意:队列中的数据是先进先出的。
# 导入队列模块
import queue
# 也可以用下面这种方式之间导入到队列类
from multiprocessing import Queue
# 1.生成一个队列对象
q = queue.Queue(3) # 括号内可以传数字,表示队列可以最大存放的数据量,不传有一个很大的默认值
# 2.给队列存数据
q.put(111)
print(q.full()) # 判断当前队列是否存满
q.put(222)
print(q.empty()) # 判断当前队列是否为空
q.put(333)
print(q.full())
# q.put(444) # 当给队列存的数据个数超过队列的最大存放数,队列会进入阻塞状态等待位置
# 3.从队列中取值
v1 = q.get()
v2 = q.get()
v3 = q.get()
# v4 = q.get() 当队列中没有数据的时候,在次取值会使得队列进入阻塞
v5 = q.get_nowait() # 当队列中没有数据可取的时候,就报错
v6 = q.get(timeout=3) # 没有数据原地等待3秒,然后报错
print(v1,v2,v3)
# 总结:
'''
q.full()
q.empty()
q.get_nowait()
这三个方法在多进程下是不精确的
'''
IPC机制:
1.子进程和主进程之间的通信
2.子进程和子进程之间的通信
from multiprocessing import Queue,Process
def cosumer1(q):
# 在子进程中存数据
q.put('我是队列存的信息')
print('子进程1')
def cosumer2(q):
# 在子进程中取数据
print(q.get())
if __name__ == '__main__':
q = Queue()
p = Process(target=cosumer1,args=(q,))
p1 = Process(target=cosumer2,args=(q,))
p.start()
p1.start()
# 在主进程取出数据
# print(q.get())
补充:后进先出q、优先级q
import queue
q = queue.LifoQueue(3)
q.put(11)
q.put(22)
print(q.get()) # 后进先出,后放入的数据先取出来
q = queue.PriorityQueue(3)
q.put((1,'444')) # put方法里面放的是一个元组,元组第一个元素表示优先级,第二个是需要放的数据
q.put(((-3,32324)))
q.put((10,'434'))
print(q.get()) # 优先级数字越小的级别越高,优先取出
5. 进程的综合应用--生产者消费者模型
from multiprocessing import Queue,Process,JoinableQueue
import time
import random
# 生产者子进程
def producer(name,food,q):
for i in range(5):
print('%s生产了%s%s'%(name,food,i))
time.sleep(random.randint(1,3))
q.put(food)
def consumer(name,q):
# 消费者一直在吃,进入循环
while True:
food = q.get() # 当队列中没有东西的时候,该子进程会被卡住,进入阻塞状态
print('%s吃了%s'%(name,food))
q.task_done() # 该方法属于JoinableQueue,作用是告诉队列你已经从队列中取出一个数据并且处理完毕了
if __name__ == '__main__':
# 将q = Queue()改成下面的方法创建队列
q = JoinableQueue()
# 两个生产者,分别生产的东西放进队列中
p1 = Process(target=producer,args=('zhang','包子',q))
p2 = Process(target=producer, args=('yang', '粥', q))
# 消费者从队列中取出东西吃掉
c1 = Process(target=consumer,args=('www',q))
p1.daemon = True # 守护主进程,主进程结束杀死子进程
p2.daemon = True
c1.daemon = True
p1.start()
p2.start()
c1.start()
p1.join()
p2.join() # 等待生产者生产完毕在执行下面的代码
q.join() # 等待队列中所有的数据被取完之后再执行下述代码
# JoinableQueue类
"""
该类是在queue类上的基础上添加了一个计数器,每当往队列中存放一个数据时,计数器会加1;
当你调用task_done时,计数器减1
q.join() 等待计数器为0的时候在执行该方法下面的代码
"""
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:进程 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 