作者经历了多次基于HBase实现全量与增量数据的迁移测试,总结了在使用HBase进行数据迁移的多种实践,本文针对全量与增量数据迁移的场景不同,提供了1+2的技巧分享。
HBase全量与增量数据迁移的方法
1.背景
在HBase使用过程中,使用的HBase集群经常会因为某些原因需要数据迁移。大多数情况下,可以用离线的方式进行迁移,迁移离线数据的方式就比较容易了,将整个hbase的data存储目录进行搬迁就行,但是当集群数据量比较多的时候,文件拷贝的时间很长,对业务影响时间也比较长,往往在设计的时间窗口无法完成,本文给出一种迁移思路,可以利用HBase自身的功能,对集群进行迁移,减少集群业务中断时间
2.简介
大家都知道HBase有snapshot快照的功能,利用快照可以记录某个时间点表的数据将其保存快照,在需要的时候可以将表数据恢复到打快照时间时的样子。我们利用hbase的snapshot可以导出某个时间点的全量数据。
因为实际的业务还在不停的写入表中,除了迁移快照时间点之前的全量数据,我们还需要将快照时间点后源源不断的增量数据也迁移走,这里如果能采用双写的方式,将数据写入两个集群就好了,但是现实的业务不会这样做,如果这样做还得保证双写的事务一致性。于是可以利用HBase的replication功能,replication功能本身就是保留了源集群的WAL日志记录,去回放写入到目的集群,这样一来用户业务端->原始集群->目的集群便是个串形的数据流,且由HBase来保证数据的正确性。
所以这个迁移的方法就是利用snapshot迁移全量数据,利用replication迁移增量数据。
3.迁移步骤
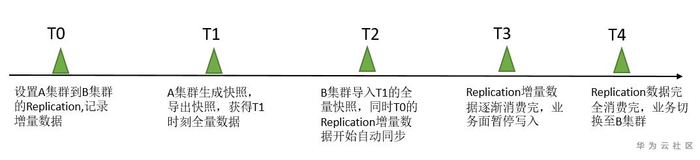

上图给出了迁移的整个时间线流程,主要有这么5个时间点。
T0: 配置好老集群A集群到新集群B的Replication关系,Replication的数据由A集群同步到集群B,将表设置成同步,从此刻开始新写入A集群表的数据会保留在WAL日志中;
T1: 生成该时间点的全量数据,通过创建快照,以及导出快照数据的方式将该时间点的数据导出到新集群B;
T2: 新集群B将T1时刻的快照数据导入,此时新集群B中会由快照创建出表,此时老集群A集群上设置的Replication的关系会自动开始将T0时刻保留的WAL日志回放至新集群B的表中,开始增量数据同步。
T3: 由于从T0-T3之间的操作会花费一段时间,此时会积累很多WAL日志文件,需要一定的时间来同步至新集群,这里需要去监控一下数据同步情况,等老集群WAL被逐渐消费完,此时可以将老集群的写业务停止一下并准备将读写业务全部切到新集群B。
T4: T3-T4之间应该是个很短的时间,整个迁移也只有这个时间点会有一定中断,此时是将业务完全切到新集群B,至此迁移完成。
4.操作涉及的命令
一、设置集群A和集群B的peer关系
在源集群hbase shell中, 设定peer
add_peer 'peer_name','ClusterB:2181:/hbase'
二、在集群A的表中设置replication属性
假设目标表名为Student,先获取Family=f
进入hbase shell中,
alter 'Student',{NAME => 'f',REPLICATION_SCOPE => '1'}
三、给集群A的表创建快照
在hbase shell中
snapshot 'Student','Student_table_snapshot'
四、在A集群中导出快照
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot Student_table_snapshot -copy-to /snapshot-backup/Student
五、将快照数据放置到集群B的对应的目录下
上面命令会导出2个目录,一个是快照元数据,一个是原始数据
将元数据放到/hbase/.hbase-snapshot中,将原始数据放到/hbase/archive目录中
由于hbase的archive目录会有个定时清理,这里可以提前将集群B的master的hbase.master.cleaner.interval值设置大点,避免拷贝过程中发生碰巧发生了数据清理。
如果集群B中没有对应的目录,可以提前创建
hdfs dfs -mkdir -p /hbase/.hbase-snapshot
hdfs dfs -mkdir -p /hbase/archive/data/default/
移动导出的snapshot文件到snapshot目录
hdfs dfs -mv /snapshot-backup/Student/.hbase-snapshot/Student_table_snapshot /hbase/.hbase-snapshot/
hdfs dfs -mv /snapshot-backup/Student/archive/data/default/Student /hbase/archive/data/default
六、在新集群B中恢复表的快照
进入hbase shell
restore_snapshot 'Student_table_snapshot'
恢复完成后,记得将集群B的hmaster中hbase.master.cleaner.interval的值调整回来。
HBase增量数据迁移的方法
1.概览
本章主要是想谈一下如何给HBase做增量数据的迁移,也就是迁移实时数据。上文中提到HBase增量数据迁移可以使用Replication的方式去做,但是在实际搬迁时,要给原集群设置Replication可能需要重启,这样会影响业务,我们需要做到不停机迁移才行。
2.WAL原理
正常情况下,HBase新增的数据都是有日志记录的,数据在落盘成HFile之前,任何一个Put和Delete操作都是记录日志并存放在WALs目录中,日志中包含了所有已经写入Memstore但还未Flush到HFile的更改(edits)。
默认情况下每个RegionServer只会写一个日志文件,该RS管理的所有region都在向这一个日志文件写入Put和Delete记录,直到日志文件大小达到128MB(由hbase.regionserver.hlog.blocksize设置)后roll出一个新的日志文件,总共可以roll出32个日志文件(由hbase.regionserver.maxlogs设置)。
如果日志文件未写满128MB,RegionServer间隔1小时也会roll出新一个新日志文件(由hbase.regionserver.logroll.period设置)。
当日志文件中涉及的所有region的记录都flush成HFile后,这个日志文件就会转移至oldWals目录下归档, Master没间隔10分钟(hbase.master.cleaner.interval)会检查oldWALs目录下的过期日志文件,当文件过期时会被Master清理掉,(日志过期时间由hbase.master.logcleaner.ttl控制)。
RegionServer默认间隔1小时(由hbase.regionserver.optionalcacheflushinterval设置)会对它管理的region做一次flush动作,所以WALs目录中一直会有新的日志文件生成,并伴随着老的日志文件移动到oldWALs目录中。
3.迁移方式
一、迁移oldWALs目录中的文件,使用WALPlayer回放
由于日志文件文件最终移动到oldWALs目录下,只需要写个脚本,定时检查oldWALs目录下是否有新文件生成,如果有文件,则move至其他目录,并使用WALPlayer工具对这个目录进行回放。
优点:无代码开发量,仅需脚本实现
缺点:无法做到实时,因为从数据写入到最后到达oldWAL目录会间隔很长时间。
二、开发独立工具,解析日志文件,写入目的集群
在网上查找迁移方法的时候了解到了阿里开发了一个专门的HBase迁移工具,可以实现不停机。通过阅读其设计BDS - HBase数据迁移同步方案的设计与实践了解到阿里开发了应用去读取HBase的WAL日志文件并回放数据至目的集群。
优点:可以做到实时;
缺点:需要一定的代码开发量;
要做出这样一个工具,需要了解上面说的WAL文件归档的原理以及日志回放工具WALPlayer,下面简单说一下可以怎么去实现。
独立工具实现
这里简单说明下如何去做这样一个工具,只介绍读取WAL方面,任务编排就不描述了:
1、定时扫描WALs目录获取所有的日志文件,这里按ServerName去分组获取,每个分组内根据WAL文件上的时间戳排序:
● 获取所有RS的ServerName
ClusterStatus clusterStatus = admin.getClusterStatus();
Collection<ServerName> serverNames = clusterStatus.getServers();
● 根据ServerName去组成Path获取日志
Path rsWalPath = new Path(walPath, serverName.getServerName());
List<FileStatus> hlogs = getFiles(fs, rsWalPath, Long.MIN_VALUE, Long.MAX_VALUE);
● getFiles()参考HBase源码中WALInputFormat.java中的实现,可以指定时间范围去取日志文件
private List<FileStatus> getFiles(FileSystem fs, Path dir, long startTime, long endTime)
throws IOException {
List<FileStatus> result = new ArrayList<FileStatus>();
LOG.debug("Scanning " + dir.toString() + " for WAL files");
FileStatus[] files = fs.listStatus(dir);
if (files == null) return Collections.emptyList();
for (FileStatus file : files) {
if (file.isDirectory()) {
// recurse into sub directories
result.addAll(getFiles(fs, file.getPath(), startTime, endTime));
} else {
String name = file.getPath().toString();
int idx = name.lastIndexOf('.');
if (idx > 0) {
try {
long fileStartTime = Long.parseLong(name.substring(idx+1));
if (fileStartTime <= endTime) {
LOG.info("Found: " + name);
result.add(file);
}
} catch (NumberFormatException x) {
idx = 0;
}
}
if (idx == 0) {
LOG.warn("File " + name + " does not appear to be an WAL file. Skipping...");
}
}
}
return result;
}
2、对于取到的每一个WAL文件,当做一个任务Task执行迁移,这个task主要有下面一些步骤:
● 使用WALFactory为每个日志文件创建一个Reader
WAL.Reader walReader = WALFactory.createReader(fileSystem, curWalPath, conf);
● 通过Reader去读取key和edit,并记录下position,为了加快写入速度,这里可以优化为读取多个entry
WAL.Entry entry = walReader.next();
WALKey walKey = entry.getKey();
WALEdit walEdit = entry.getEdit();
long curPos = reader.getPosition();
● 记录position的目的是为了Reader的reset以及seek,因为这个原始WAL文件还正在写入的时候,我们的Reader速度很可能大于原WAL的写入速度,当Reader读到底的时候,需要等待一段时间reset然后再重新读取entry
WAL.Entry nextEntry = reader.next();
if (nextEntry == null) {
LOG.info("Next entry is null, sleep 10000ms.");
Thread.sleep(5000);
curPos = reader.getPosition();
reader.reset();
reader.seek(curPos);
continue;
}
● 在读取WAL的过程中很可能会遇到日志转移到oldWALs目录下,这个时候捕获到FileNotFoundException时,需要重新生成一个oldWALs目录下Reader,然后设置curPos继续读取文件,这个时候如果再次读取到文件最后的时候,就可以关闭Reader了,因为oldWALs中的日志文件是固定大小的,不会再有追加数据。
这里需要注意的是这个参数hbase.master.logcleaner.ttl不能设置过小,否则会出现这个在oldWALs目录下的日志文件还没读取完被清理掉了。
Path oldWALPath = new Path(oldWalPath, walFileName);
WAL.Reader reader = WALFactory.createReader(fileSystem, oldWALPath, conf);
reader.seek(curPos)
● 根据通过WAL.Reader可以读取到walKey,walEdit进而解析出Cell并写入目的集群,这个可以参考WALPlay的map()方法。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:全量、增量数据在HBase迁移的多种技巧实践 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 