作者
刘旭,腾讯云高级工程师,专注容器云原生领域,有多年大规模 Kubernetes 集群管理经验,现负责腾讯云 GPU 容器的研发工作。
背景
目前 TKE 已提供基于 qGPU 的算力/显存强隔离的共享 GPU 调度隔离方案,但是部分用户反馈缺乏 GPU 资源的可观测性,例如无法获取单个 GPU 设备的剩余资源,不利于 GPU 资源的运维和管理。在这种背景下,我们希望提供一种方案,可以让用户在 Kubernetes 集群中直观的统计和查询 GPU 资源的使用情况。
目标
在目前 TKE 共享 GPU 调度方案的基础上,从以下几个方面增强 GPU 设备的可观测性:
-
支持获取单个 GPU 设备的资源分配信息。
-
支持获取单个 GPU 设备的健康状态。
-
支持获取某个节点上各 GPU 设备信息。
-
支持获取 GPU 设备和 Pod / Container 关联信息。
我们的方案
我们通过 GPU CRD 扫描物理 GPU 的信息,并在 qGPU 生命周期中更新使用到的物理 GPU 资源,从而解决在共享 GPU 场景下缺少可见性的问题。
-
自定义 GPU CRD:每个 GPU 设备对应一个 GPU 对象,通过 GPU 对象可以获取 GPU 设备的硬件信息,健康状态以及资源分配情况。
-
Elastic GPU Device Plugin:根据 GPU 设备的硬件信息创建 GPU 对象,定期更新 GPU 设备的健康状态。
-
Elastic GPU Scheduler:根据 GPU 资源使用情况调度 Pod,同时将调度结果更新到 GPU 对象。
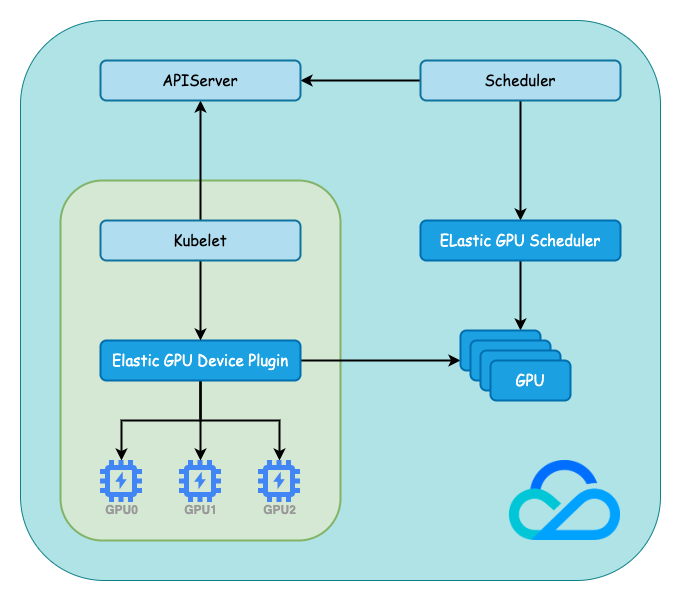

TKE GPU CRD 设计
apiVersion: elasticgpu.io/v1alpha1
kind: GPU
metadata:
labels:
elasticgpu.io/node: 10.0.0.2
name: 192.168.2.5-00
spec:
index: 0
memory: 34089730048
model: Tesla V100-SXM2-32GB
nodeName: 10.0.0.2
path: /dev/nvidia0
uuid: GPU-cf0f5fe7-0e15-4915-be3c-a6d976d65ad4
status:
state: Healthy
allocatable:
tke.cloud.tencent.com/qgpu-core: "50"
tke.cloud.tencent.com/qgpu-memory: "23"
allocated:
0dc3c905-2955-4346-b74e-7e65e29368d2:
containers:
- container: test
resource:
tke.cloud.tencent.com/qgpu-core: "50"
tke.cloud.tencent.com/qgpu-memory: "8"
namespace: default
pod: test
capacity:
tke.cloud.tencent.com/qgpu-core: "100"
tke.cloud.tencent.com/qgpu-memory: "31"
每个 GPU 物理卡对应一个 GPU CRD,通过 GPU CRD 可以清楚了解每张卡的型号,显存等硬件信息,同时通过 status 可以获取每个 GPU 设备的健康状态和资源分配情况。
TKE GPU 调度过程
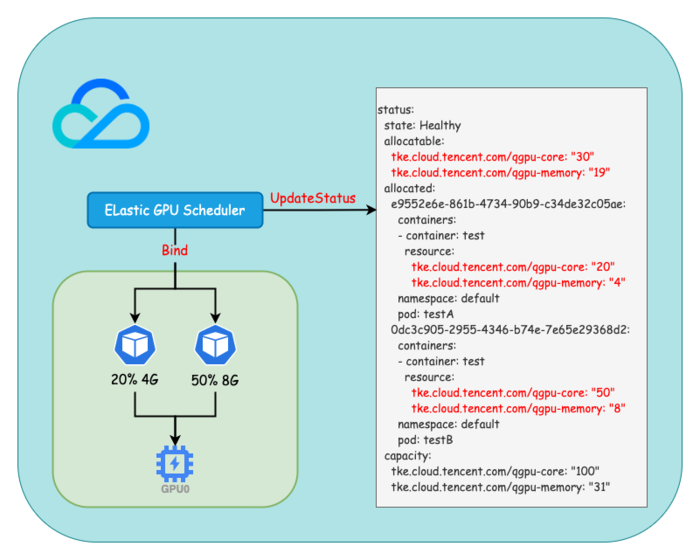
Kubernetes 提供了 Scheduler Extender 用于对调度器进行扩展,用于满足复杂场景下的调度需求。扩展后的调度器会在调用内置预选策略和优选策略之后通过 HTTP 协议调用扩展程序再次进行预选和优选,最后选择一个合适的 Node 进行 Pod 的调度。
在 TKE Elastic GPU Scheduler(原 TKE qGPU Scheduler),我们结合了 GPU CRD 设计,在调度时首先会根据 status.state 过滤掉异常 GPU 设备,然后根据 status.allocatable 选择剩余资源满足需求的 GPU 设备,在最终完成调度时更新 status.allocatable 和 status.allocated 。
TKE GPU 分配过程
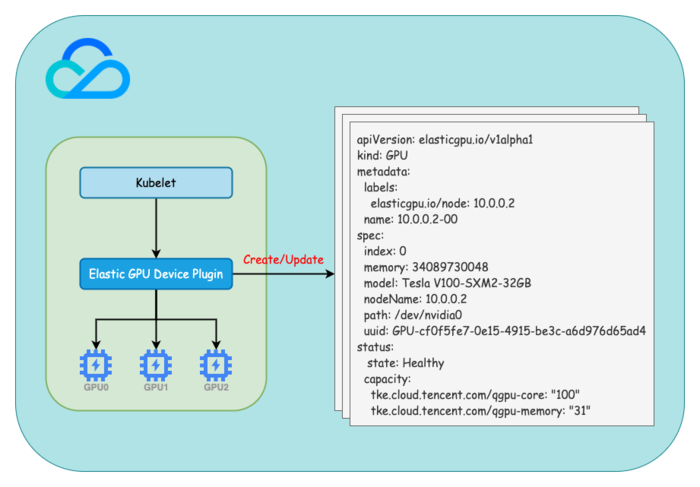
Kubernetes 提供了 Device Plugin 机制用于支持 GPU FPGA 等硬件设备,设备厂商只需要根据接口实现 Device Plugin 而不需要修改 Kubernetes 源码,Device Plugin 一般以 DaemonSet 的形式运行在节点上。
我们在 TKE Elastic GPU Device Plugin(原 TKE qGPU Device Plugin)启动时会根据节点上 GPU 设备的硬件信息创建 GPU 对象,同时会定期检查 GPU 设备的健康状态并同步到 GPU 对象的 status.state。
总结
为了解决目前 TKE 集群内 GPU 资源可观测性缺失的问题,我们引入了 GPU CRD,用户可以直观的统计和查询集群内 GPU 资源的使用情况,目前这套方案已和 qGPU 完成整合,在 TKE 控制台安装 qGPU 插件时选择使用 CRD 即可开启。
目前 TKE qGPU 已全量上线,详情请戳:https://cloud.tencent.com/document/product/457/61448
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
④公众号后台回复【光速入门】,可获得腾讯云专家5万字精华教程,光速入门Prometheus和Grafana。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:TKE qGPU 通过 CRD 管理集群 GPU 卡资源 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 