1.什么是knn算法
俗话说:物以类聚,人以群分。看一个人什么样,看他身边的朋友什么样就知道了(这里并没歧视谁,只是大概率是这样)
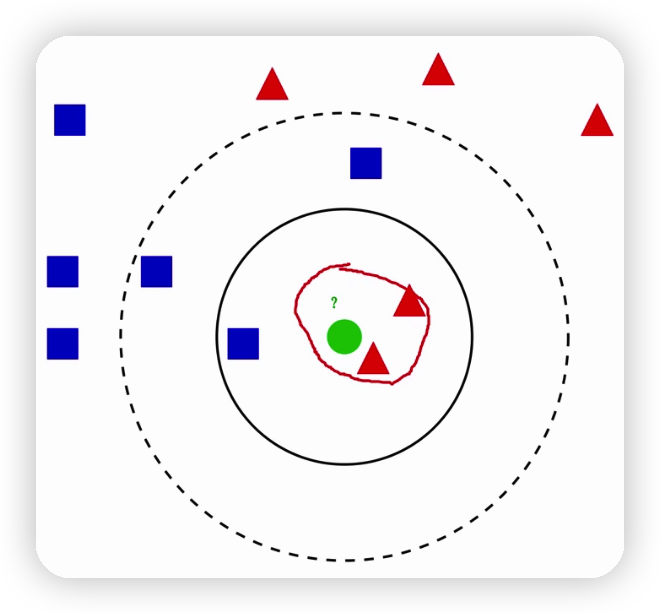
对于判断下图绿色的球是哪种数据类型的方法就是根据寻找他最近的k个数据,根据k的值来推测新数据的类型。
比如下图离绿球最近的红三角有两个,蓝方块有一个,因此推测绿色的球为红色的三角,这就是knn算法的思想

2.算法原理
2.1通用步骤
2.1.1计算距离
刚才说knn算法的思想就是根据当前数据最近的k个数据的值来判断当前数据的类型,这就要先计算出当前数据到其它数据的距离,可以使用欧几里得距离(所有的距离求出来之后各自平方并相加,然后对相加的结果进行开放)或马氏距离
2.1.2升序排列
将上一步计算的每个顶点到该点的距离进行排序,一般将序列变为升序
2.1.3取前K个
对已经排序好的距离序列,取前k个即可
2.1.4加权平均
比方取的是前7个元素(即k=7),前两个值特别小,也即和需要判断其类型的元素距离特别近,则这两个元素的权值就可以设置为很大;而剩余5个元素则离相对比较远一点,则这五个元素对应的权值也就比较小,这样算出来的加权平均算出来的元素的类型与真实数据类型的概率才是最大的,如果直接取算术平均则相差可能会比较大
注意:此处并不能计算算术平均值
2.2 K的选取
2.2.1 K的值太大
如果选的k太大,会导致分类模糊,比如:假设有1000个已知的数据点,然后k取800,无论你怎么分基本都是你这1000个数据组成的数据集的状态,因为800个已经可以涵盖绝大多数的数据的类型了,所以会导致分类模糊
2.2.2 K的值太小
受个例影响,波动较大
2.3 如何选取K
2.3.1 经验
比方说先取一个5把算法跑一边,发现是概率是50,在取个6发现概率是60,在取个7发现概率是55,则k的合适的值就是6,可以一个一个去尝试
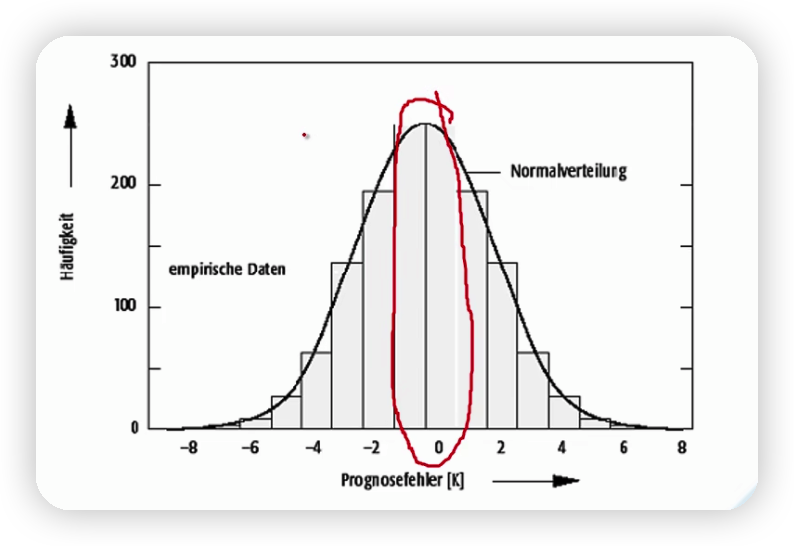
2.3.2 均方根误差
取下图(近似均方根误差的图)峰值(准确性最高)对应的k的值即可
3.实战应用
3.1 癌症检测数据
数据获取方法:
链接:https://pan.baidu.com/s/1w8cyvknAazrAYnAXdvtozw
提取码:zxmt
数据部分内容如下
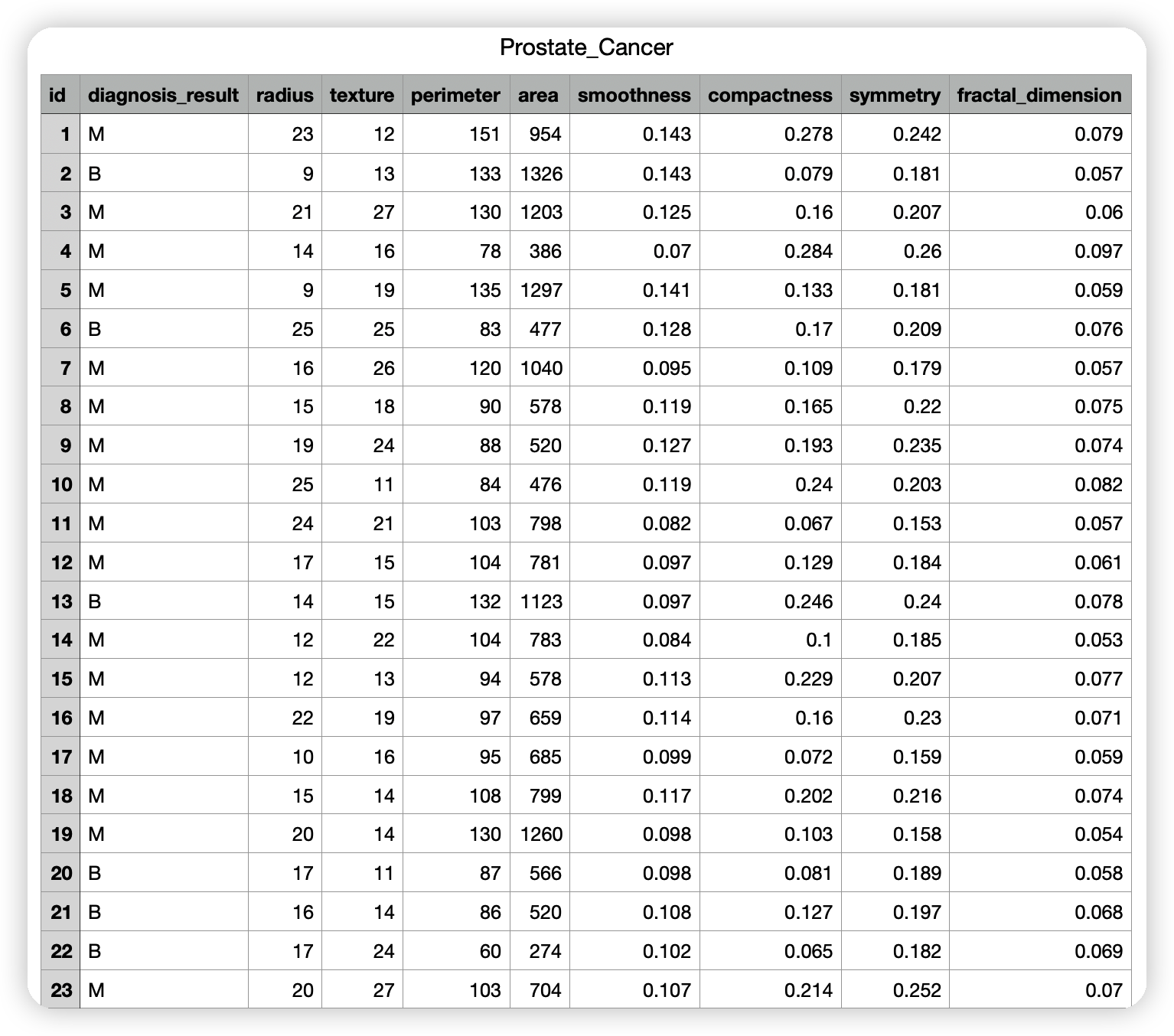
目的:给一个癌症检测数据,然后根据该数据判断该患者是良性的还是恶性的
import csv
#读取
import random
with open('Prostate_Cancer.csv','r') as file:
reader = csv.DictReader(file)
datas=[row for row in reader]
#分组
random.shuffle(datas)#将所有数据打乱,相当于完牌之前,先洗牌
n=len(datas)//3#将所有数据集分成两份,一份当做测试集,一份当做训练集 两个斜杠表示整除
#0到n-1为测试集
test_set=datas[0:n]
#n到后面所有数据为训练集
train_set=datas[n:]
#knn
#算距离
def distance(d1,d2):
res=0#欧几里得距离需要用一个变量来存距离的平方和
for key in("radius","texture", "perimeter","area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res+=(float(d1[key])-float(d2[key]))**2#对同一维度的值进行相减之后进行平方
return res**0.5#开方
k=5#测试k的值即可
def knn(data):
#1.算距离
res=[
{"result": train['diagnosis_result'],"distance": distance(data,train)}
for train in train_set
]
#2.排序-升序
res=sorted(res, key=lambda item:item['distance'])#将res里的结果按照距离的大小进行升序排列
#3.取前k个元素
res2=res[0:k]
#4.加权平均
result={'B':0,'M':0}
#先算总距离
sum=0
for r in res2:
sum+=r['distance']
for r in res2:
result[r['result']]+=1-r['distance']/sum#距离越近distance就越小除以总距离之后就越小,所以用1减去之后就越大,保证越近的距离权值越大的要求
# print("经过knn算法得到的概率为:")#经过knn算法判断得到的结果
# print(result)
# print("原数据的结果为:"+data['diagnosis_result'])#原数据的结果
if (result['B'] > result['M']):
return 'B'
else:
return 'M'
#knn(test_set[0])#在测试集里面找一个数据表示当前需要判断类型的数据
#测试阶段
correct=0#表示原结果与knn算法执行结果相同的次数
for test in test_set:
result=test['diagnosis_result']#获取原数据的结果
result2=knn(test)#knnu算法之后的结果
if(result == result2):
correct+=1
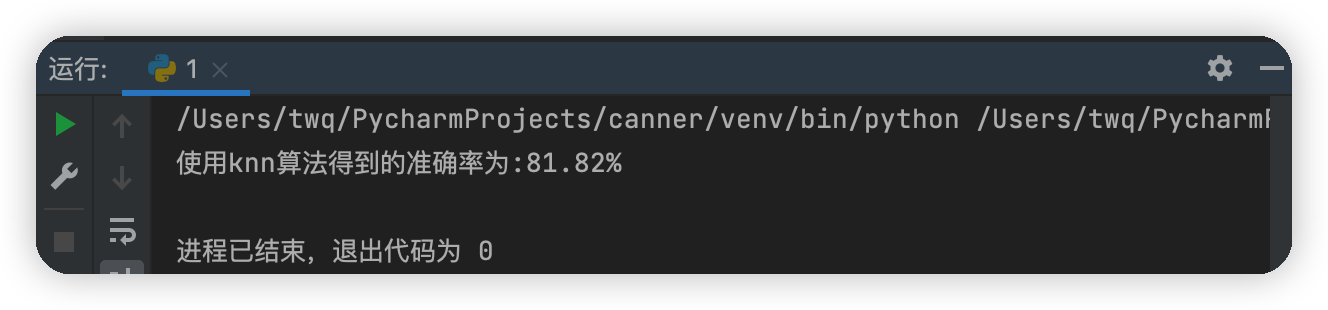
print("使用knn算法得到的准确率为:{:.2f}%".format(100*correct/len(test_set)))
运行结果图
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:knn算法详解 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 