摘要:多模态认知智能是AI人工智能当前发展的主流趋势之一,其核心是以多模态知识的获取,表示与推理为主要内容的跨模态知识工程与认知智能,也是为了更好的处理多模态的数据,需要融合多种感知模态和智能处理技术。
本文分享自华为云社区《GPT-4发布,AIGC时代的多模态还能走多远?系列之三:多模态认知智能》,作者:码上开花_Lancer。
上两篇文章介绍了AIGC未来已来和AIGC的阿克琉斯之踵,了解到AIGC当前的发展趋势和当前的一些不足之处,接下来给大家介绍AIGC时代的多模态技术的发展。
多模态认知智能是AI人工智能当前发展的主流趋势之一,其核心是以多模态知识的获取,表示与推理为主要内容的跨模态知识工程与认知智能,也是为了更好的处理多模态的数据,需要融合多种感知模态和智能处理技术。
01 多模态认知智能:研究框架
多模态认知智能是一种融合多种感知模态和智能处理技术的人工智能,旨在建立更加丰富、灵活和可信赖的人机交互平台。为此,需要研究一套完整的多模态认知智能研究框架,该框架应包含以下几个方面:
- 跨模态搜索:对于用户输入的问题或查询,系统能够同时从不同类型的媒介(包括文字、图片、视频、声音等)中检索相关信息,并将查询结果进行融合。
- 跨模态推荐:根据用户的兴趣偏好和历史行为,系统可以向用户推荐各种类型的内容,包括文章、音乐、电影、商品等,同时也能够将推荐内容进行个性化定制,提高用户的满意度。
- 跨模态问答:对于用户提出的问题,系统能够通过多种途径获取相关信息并进行自动回答。例如,用户可以通过文字或语音提出问题,系统会自动识别问题的语义和意图,并给出答案或建议。
- 跨模态生成:系统能够根据用户需求,自动生成各种类型的内容,包括文本、音频、视频、图像等。例如,系统可以根据用户提供的关键词生成一段语音介绍、一张图片、一份文章等。
- 多模态知识应用:系统能够通过自动学习和知识图谱等技术,从多种知识源中获取信息,并进行多模态应用。例如,系统可以将图像、文本和语音等不同类型的信息进行链接和融合,实现多模态信息展示和分析。 这些组成部分相互交织,形成了一个完整的多模态认知智能研究框架的基础。在实际应用中,多模态认知智能技术可以应用于各种领域,包括智能客服、智能家居、智能医疗、智能交通等。可以预见的是,未来多模态认知智能技术将会不断发展,为人类的生产和生活带来更多的便利和创新。
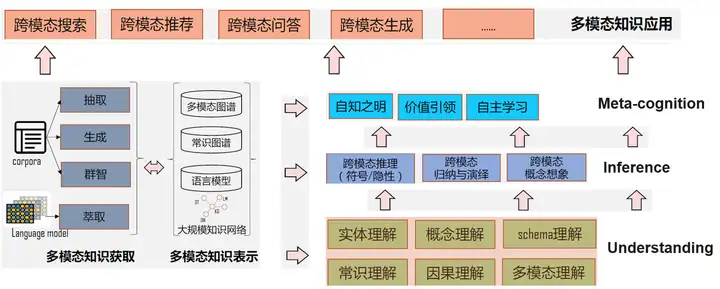
(多模态认知智能研究框架,图片来自网络)
02 多模态认知智能:两种实现路径
我们明白多模态认知智能研究框架以后,对于多模态认知智能,它是怎么样实现的呢?
多模态大模型是一种连接主义和经验主义相结合的实现路径。它的核心思想是利用海量预训练数据来构建一个大规模的神经网络模型,能够自动学习和提取多模态数据中的特征和关系,并实现对多种语言、图像、音频等多种形式的信息进行联合理解。该方法具有概率关联、简单鲁棒等优点,但在学习逻辑关系等方面仍有局限性。 多模态知识工程则是一种符号主义的实现路径,主要依赖专家系统和知识图谱等手段,通过对精选数据和专家知识的整合和转化,将其转换成符号知识,实现对多模态数据的解析和分析。该方法具有易推理、可控、可干预、可解释等特点,但在信息损失方面存在一定的问题。 综合来看,多模态大模型和多模态知识工程各有优缺点,需要根据应用场景和需求进行选择和设计。在未来的研究中,我们需要进一步探索如何更好地结合两种实现路径,充分利用它们各自的优势,实现多模态认知智能的高效、准确和可解释性。 数据转换成符号知识的过程往往伴随着巨大的信息损失,隐性知识、难以表达的知识是损失信息中的主体, 在AIGC大模型时代,多模态知识工程依然不可或缺。

(以上图来自网络)
03 多模态知识图谱(MMKG):两种主流形式
多模态知识工程中有一种常用的方法是利用知识图谱,这种方法被称为多模态知识图谱(MMKG)。与传统知识图谱不同,MMKG以多模态数据作为源头,从多方面描述实体和关系,构建出一个可以跨越多模态的知识体系。在MMKG中,多模态数据不仅仅作为文字符号实体的关联属性存在,还可以作为图谱中的实体存在,可与现有实体发生广泛关联。 MMKG的优势在于它能够消除多模态数据的异构性,将它们有机地结合在一起,使得系统能够实现对多模态数据的更加全面和深入的理解。同时,MMKG也能够提高数据的可发现性和可重用性,使得数据共享变得更加容易。
在实际应用中, 例如,假设你需要在家里搭建一套智能家居系统,这个系统需要支持语音控制、自动化定时等多种功能。那么,在建设过程中,MMKG就可以帮助系统对运作环境、设备状态、用户需求等方面的多模态数据进行综合分析和优化,从而提高系统的智能性、可靠性和适应性。 另一个具有代表性的例子是医疗领域的智能辅助诊断系统。这类系统会收集包括医学影像、实验室检查、文本记录等形式的多模态数据,利用MMKG进行知识关联、特征提取和预测策略优化等任务。通过这种方式,系统可以在医生与病人之间架起一座智能化的桥梁,让医疗决策变得更加全面、准确和科学。
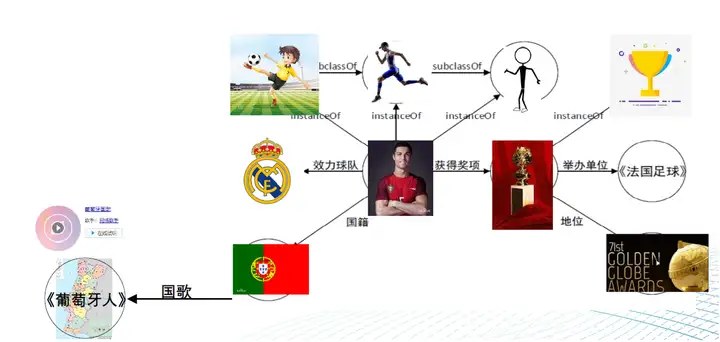
(以上图片来自文章X. Zhu, Z. Li et. al. Multi-Modal Knowledge Graph Construction and Application: A Survey, Accepted by TKDE in Dec. 2022)
MMKG已经被应用于多个领域,包括自然语言处理、计算机视觉、语音识别等。例如,在自然语言处理领域,MMKG可以将不同形式的语言信息连接起来,实现对文本、图片和音频内容的跨越式认知和分析;在计算机视觉领域,MMKG可以将图像和视频数据与其他领域的知识相结合,获得更具深度和复杂性的认知结果。 未来,随着各种智能设备的普及和多模态数据的日益增长,MMKG必将成为实现多模态认知智能的一个重要手段。我们需要进一步完善MMKG的理论框架和技术体系,在构建更加丰富和高效的多模态知识图谱的基础上,实现对多模态数据的更加准确和深刻的认知,推动人工智能技术的不断发展和应用。 总之,在多模态数据处理和应用方面,MMKG可以大大增强系统的认知和决策能力,实现人机交互的更加智能化和自然化,同时也可以促进各领域应用场景的创新和发展。
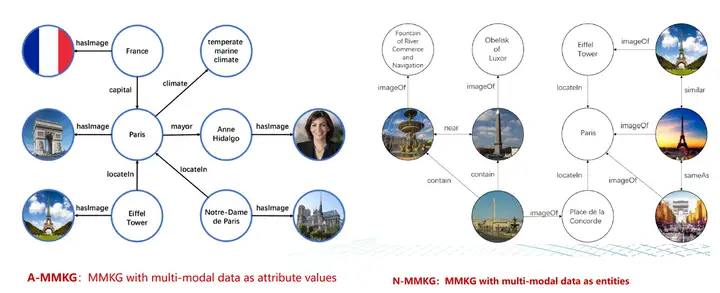
(以上图片来自文章《X. Zhu, Z. Li et. al. Multi-Modal Knowledge Graph Construction and Application: A Survey, Accepted by TKDE in Dec. 2022》)
04 AIGC多模态大模型VS大规模多模态知识图谱
在当前的自然语言处理领域中,多模态大模型和多模态知识图谱都有各自的优缺点。多模态大模型具有关联推理强、可适应多任务、人工成本低、适应能力强等优点,但其可靠程度低、知识推理能力弱、可解释性不足、训练成本高等不足之处也不容忽视。而多模态知识图谱则具有专业可信度高、可解释性强、可拓展性好等优点,但其推理能力弱、人工成本高、架构调整难等不足之处也同样存在。 针对这些不足之处,目前的研究方向主要包括以下几个方面:
- 提升模型可靠性:当前研究团队正在发掘不同模态的数据之间的潜在关系,并通过改进模型的结构和算法等方式提高其预测的准确率,从而提升模型的可靠程度。
- 强化知识推理能力:加强模型对知识的学习和推理能力,使其能够对数据背后的知识进行更深入的挖掘和分析,实现真正意义上的知识推理。
- 提升可解释性:通过增强模型的可解释性来提高其通用性和实用性,帮助人类理解和解释模型的预测结果。
- 优化训练成本:通过改进算法和并行计算技术等方式降低训练成本,提高模型的训练效率和稳定性。
- 自动化知识图谱构建:通过自动化抽取和建模技术来降低构建多模态知识图谱的人工成本,提升其可扩展性和实用性。
当前阶段,大模型与知识图谱仍应继续保持竞合关系,互相帮助,互为补充,未来的研究方向将集中在如何充分利用多模态数据,提高模型的可靠性、推理能力和可解释性,降低训练成本和构建成本,实现更加精准和智能的自然语言处理。那AIGC多模态大模型在多模态知识图谱的实际场景是怎么的呢?请期待我的下一篇文章GPT-4发布,AIGC时代的多模态还能走多远?系列之四 AIGC for MMKG。
参考:
部分内容参考来自复旦大学教授李直旭《AIGC时代的多模态知识工程思考与展望》
论文:《Google’s PaLM-E is a generalist robot brain that takes commands》
《X. Zhu, Z. Li et. al. Multi-Modal Knowledge Graph Construction and Application: A Survey, Accepted by TKDE in Dec. 2022
http://arxiv.org/abs/2206.14268 和http://arxiv.org/abs/2212.05767
原文链接:https://www.cnblogs.com/huaweiyun/p/17355053.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:一文详解多模态认知智能 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
