目录
一、爬虫介绍
1.名字解释
爬虫:spider,网络蜘蛛
2.本质原理
- 现在的所有软件原理:大部分都是
基于http请求发送和获取请求- pc端的网页
- 移动端的app
模拟发送http请求,从别人的服务端获取数据- 怎么绕开反扒:不同程序的反扒措施不一样,比较复杂,具体情况具体分析
3.爬虫原理
- 发送http请求【requests,selenium】
- 》》》 第三方服务端
- 》》》服务端响应的数据解析出想要的数据【selenium,b64】
- 》》》 入库(文件、数据库、Excel、Redis、MongoDB等等)
- scrapy:专业的爬虫框架
4.爬虫是否合法
-
爬虫其实算是擦边的行为,遵守规则的爬,不会违法。(在这里忠告各位玩家,一定要做遵纪守法的好公民,牢饭不香,缝纫机不好踩。)
-
那么爬虫的规则是什么呢?>>> 爬虫协议
-
爬虫协议:每个网站的根路径下都有
robots.txt,这个文件规定了:该网站能爬的和不能爬的数据
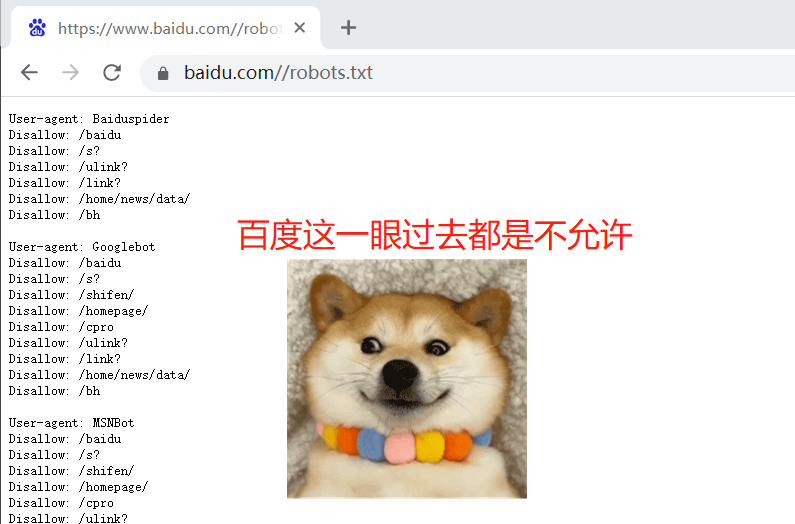

5.百度其实就是个大爬虫
- 在百度的搜索框中输入搜索内容,回车后返回的数据,是百度数据库中的数据
- 而百度,其实在一刻不停的在互联网中爬取各个页面,链接地址>>>爬到的数据保存到自己的数据库
- 点击之后,跳转到真正的地址上去
- 核心:搜索,在海量数据中搜索出想要的数据
- SEO:免费的搜索,排名靠前
- 也叫:搜索引擎优化、关键词自然排名。
通过对站内和站外的优化来提高搜索引擎对网站的友好度,并提高网站的排名
- SEM:花钱买关键字
- 也叫:搜索引擎营销
- 除了对网站做优化以外,也可以用便捷的途径来更快的让客户找到你的网站,这种便捷的方式就是
通过付费的手段。
二、requests模块发送get请求
1.requests模块
-
模拟发送http请求的模块
-
不仅爬虫用它,后期调用第三方接口,也会用到它
-
可以做长链接短链接的转换
2.下载requests模块
-
pip3 install requests
-
本质是封装了内置模块urlib3
-
import requests res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html') print(res.text) # 响应体中的文本内容 print(res.__dict__.keys()) ''' dict_keys([ '_content', '_content_consumed', '_next', 'status_code', 'headers', 'raw', 'url', 'encoding','history', 'reason', 'cookies', 'elapsed', 'request', 'connection' ]) '''
三、get请求携带参数
1.地址栏中拼接
-
res=requests.get('https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3') print(res.text)
2.使用params参数携带
-
res = requests.get('https://www.baidu.com/s', params={ 'wd': '美女', 'name': 'lqz' }) print(res.text)
四、url编码和解码
-
‘美女’被编码后 >>> E7%BE%8E%E5%A5%B3
-
from urllib import parse res = parse.quote('美女') print(res) # E7%BE%8E%E5%A5%B3 res = parse.unquote('%E7%BE%8E%E5%A5%B3') print(res) # 美女
五、携带请求头
1.前提
http请求,有请求头,有些网站就是通过请求头来做反扒
2.情况:爬取某个网站,不能正常返回 >>> 说明请求模拟的不像
-
User-Agent:
- 客户端类型:浏览器,手机端浏览器,爬虫类型,程序,scrapy。一般伪造成浏览器。
-
referer:上次访问的地址
- Referer:https://www.lagou.com/gongsi/
- 如果要登录,模拟向登录接口发送请求
- 正常操作:必须在登录页面上才能干这事
- 如果没有携带referer,网站就会认为你是恶意的,拒绝掉
- 图片防盗链
-
cookie:认证后的cookie,就相当于登录了
-
header
# header={ # # 客户端类型 # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36' # } # res=requests.get('https://dig.chouti.com/',headers=header) # print(res.text
六、携带cookie
# 4 请求中携带cookie#
## 方式一:直接带在请求头中
#模拟点赞
# data={
# 'linkId':'36996038'
# }
# header={
# # 客户端类型
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
# #携带cookie
# 'Cookie':'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiI3MzAyZDQ5Yy1mMmUwLTRkZGItOTZlZi1hZGFmZTkwMDBhMTEiLCJleHBpcmUiOiIxNjYxNjU0MjYwNDk4In0.4Y4LLlAEWzBuPRK2_z7mBqz4Tw5h1WeqibvkBG6GM3I; __snaker__id=ozS67xizRqJGq819; YD00000980905869%3AWM_TID=M%2BzgJgGYDW5FVFVAVQbFGXQ654xCRHj8; _9755xjdesxxd_=32; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1666756750,1669172745; gdxidpyhxdE=W7WrUDABQTf1nd8a6mtt5TQ1fz0brhRweB%5CEJfQeiU61%5C1WnXIUkZH%2FrE4GnKkGDX767Jhco%2B7xUMCiiSlj4h%2BRqcaNohAkeHsmj3GCp2%2Fcj4HmXsMVPPGClgf5AbhAiztHgnbAz1Xt%5CIW9DMZ6nLg9QSBQbbeJSBiUGK1RxzomMYSU5%3A1669174630494; YD00000980905869%3AWM_NI=OP403nvDkmWQPgvYedeJvYJTN18%2FWgzQ2wM3g3aA3Xov4UKwq1bx3njEg2pVCcbCfP9dl1RnAZm5b9KL2cYY9eA0DkeJo1zfCWViwVZUm303JyNdJVAEOJ1%2FH%2BJFZxYgMVI%3D; YD00000980905869%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee92bb45a398f8d1b34ab5a88bb7c54e839b8aacc1528bb8ad89d45cb48ae1aac22af0fea7c3b92a8d90fcd1b266b69ca58ed65b94b9babae870a796babac9608eeff8d0d66dba8ffe98d039a5edafa2b254adaafcb6ca7db3efae99b266aa9ba9d3f35e81bdaea4e55cfbbca4d2d1668386a3d6e1338994fe84dc53fbbb8fd1c761a796a1d2f96e81899a8af65e9a8ba3d4b3398aa78285c95e839b81abb4258cf586a7d9749bb983b7cc37e2a3; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNjcxNzY1NzQ3NjczIn0.50e-ROweqV0uSd3-Og9L7eY5sAemPZOK_hRhmAzsQUk; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1669173865'
# }
# res=requests.post('https://dig.chouti.com/link/vote',data=data,headers=header)
# print(res.text)
## 方式二:通过cookie参数:因为cookie很特殊,一般都需要携带,模块把cookie单独抽取成一个参数,是字典类型,以后可以通过参数传入
data={
'linkId':'36996038'
}
header={
# 客户端类型
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
res=requests.post('https://dig.chouti.com/link/vote',data=data,headers=header,cookies={'key':'value'})
print(res.text)
# 部署项目出现的可能的问题
-路径问题:ngxin,uwsgi。。。
-数据库用户名密码问题
-前端发送ajax请求问题
-浏览器中访问一下banner接口
-nginx 8080
-安全组 80 8080 3306
-转到uwsgi的8888,视图类
-虚拟环境真实环境都要装uwsgi
-启动uwsgi是在虚拟环境中启动的
七、发送post请求
###6 发送post请求
# data = {
# 'username': '616564099@qq.com',
# 'password': 'lqz123',
# 'captcha': 'cccc',
# 'remember': 1,
# 'ref': 'http://www.aa7a.cn/',
# 'act': 'act_login'
# }
# res = requests.post('http://www.aa7a.cn/user.php', data=data)
# print(res.text)
# print(res.cookies) # 响应头中得cookie,如果正常登录,这个cookie 就是登录后的cookie RequestsCookieJar:当成字典
#
# # 访问首页,携带cookie,
# # res2 = requests.get('http://www.aa7a.cn/', cookies=res.cookies)
# res2 = requests.get('http://www.aa7a.cn/')
# print('616564099@qq.com' in res2.text)
## 6.2 post请求携带数据 data={} ,json={} drf后端,打印 request.data
# data=字典是使用默认编码格式:urlencoded
# json=字典是使用json 编码格式
# res = requests.post('http://www.aa7a.cn/user.php', json={})
## 6.4 request.session的使用:当request使用,但是它能自动维护cookie
# session=requests.session()
# data = {
# 'username': '616564099@qq.com',
# 'password': 'lqz123',
# 'captcha': 'cccc',
# 'remember': 1,
# 'ref': 'http://www.aa7a.cn/',
# 'act': 'act_login'
# }
# res = session.post('http://www.aa7a.cn/user.php', data=data)
# res2 = session.get('http://www.aa7a.cn/')
# print('616564099@qq.com' in res2.text)
八、响应Response
# Response对象,有很多属性和方法
-text
-cookies
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
respone = requests.get('https://www.jianshu.com', params={'name': 'lqz', 'age': 19},headers=header)
# respone属性
print(respone.text) # 响应体的文本内容
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 响应cookie
print(respone.cookies.get_dict()) # cookieJar对象,获得到真正的字段
print(respone.cookies.items()) # 获得cookie的所有key和value值
print(respone.url) # 请求地址
print(respone.history) # 访问这个地址,可能会重定向,放了它冲定向的地址
print(respone.encoding) # 页面编码
九、获取二进制数据
###8 获取二进制数据 :图片,视频
#
# res = requests.get(
# 'https://upload.jianshu.io/admin_banners/web_images/5067/5c739c1fd87cbe1352a16f575d2df32a43bea438.jpg')
# with open('美女.jpg', 'wb') as f:
# f.write(res.content)
# 一段一段写
res=requests.get('https://vd3.bdstatic.com/mda-mk21ctb1n2ke6m6m/sc/cae_h264/1635901956459502309/mda-mk21ctb1n2ke6m6m.mp4')
with open('美女.mp4', 'wb') as f:
for line in res.iter_content():
f.write(line)
十、解析json
# 前后分离后,后端给的数据,都是json格式,
# 解析json格式
res = requests.get(
'https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=%E4%B8%8A%E6%B5%B7&query=%E8%82%AF%E5%BE%B7%E5%9F%BA&output=json')
print(res.text)
print(type(res.text))
print(res.json()['results'][0]['name'])
print(type(res.json()))
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:爬虫 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 