为什么要使用分页
我们数据表中可能会有成千上万条数据,当我们访问某张表的所有数据时,我们不太可能需要一次把所有的数据都展示出来,因为数据量很大,对服务端的内存压力比较大还有就是网络传输过程中耗时也会比较大。
通常我们会希望一部分一部分去请求数据,也就是我们常说的一页一页获取数据并展示出来。
分页的三种方式
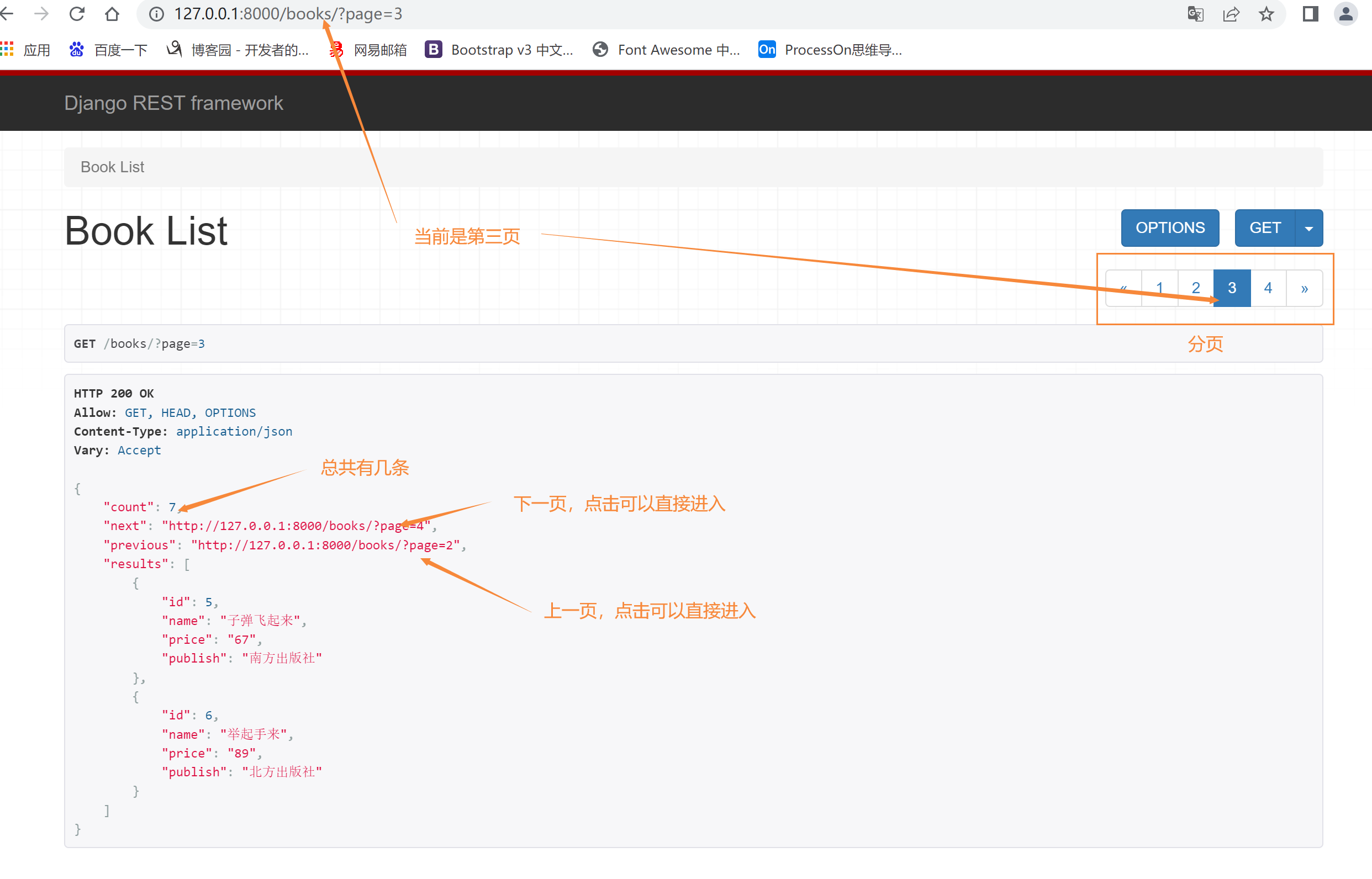
方式一:基本的分页,就是正常的查第几页每页显示多少条
model.py
from django.db import models
# Create your models here.
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.CharField(max_length=32)
def __str__(self):
return self.name
serializer.py
from rest_framework import serializers
from .models import Book, Publish
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = '__all__'
page.py
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
class CommonPageNumberPagination(PageNumberPagination):
# 有4个类属性
# 每页显示条数
page_size = 2
# 分页查询的那个参数 ?page=10
page_query_param = 'page'
# ?page=3&size=3 查询3页,每页查询3条
page_size_query_param = 'size'
# 可以通过size控制每页显示的条数,但是通过这个参数控制最多显示多少条
max_page_size = 3
view.py
from django.shortcuts import render
# Create your views here.
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import ListModelMixin
from rest_framework.viewsets import ViewSetMixin
from app01.models import Book
from app01.serializer import BookSerializer
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
# as 后面是起的别名,将我们写的类导入进来
from .page import CommonPageNumberPagination as PageNumberPagination
class BookView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
# pagination_class后面是我们自己写的类,只不过在导入的时候我们重新命名了
pagination_class = PageNumberPagination

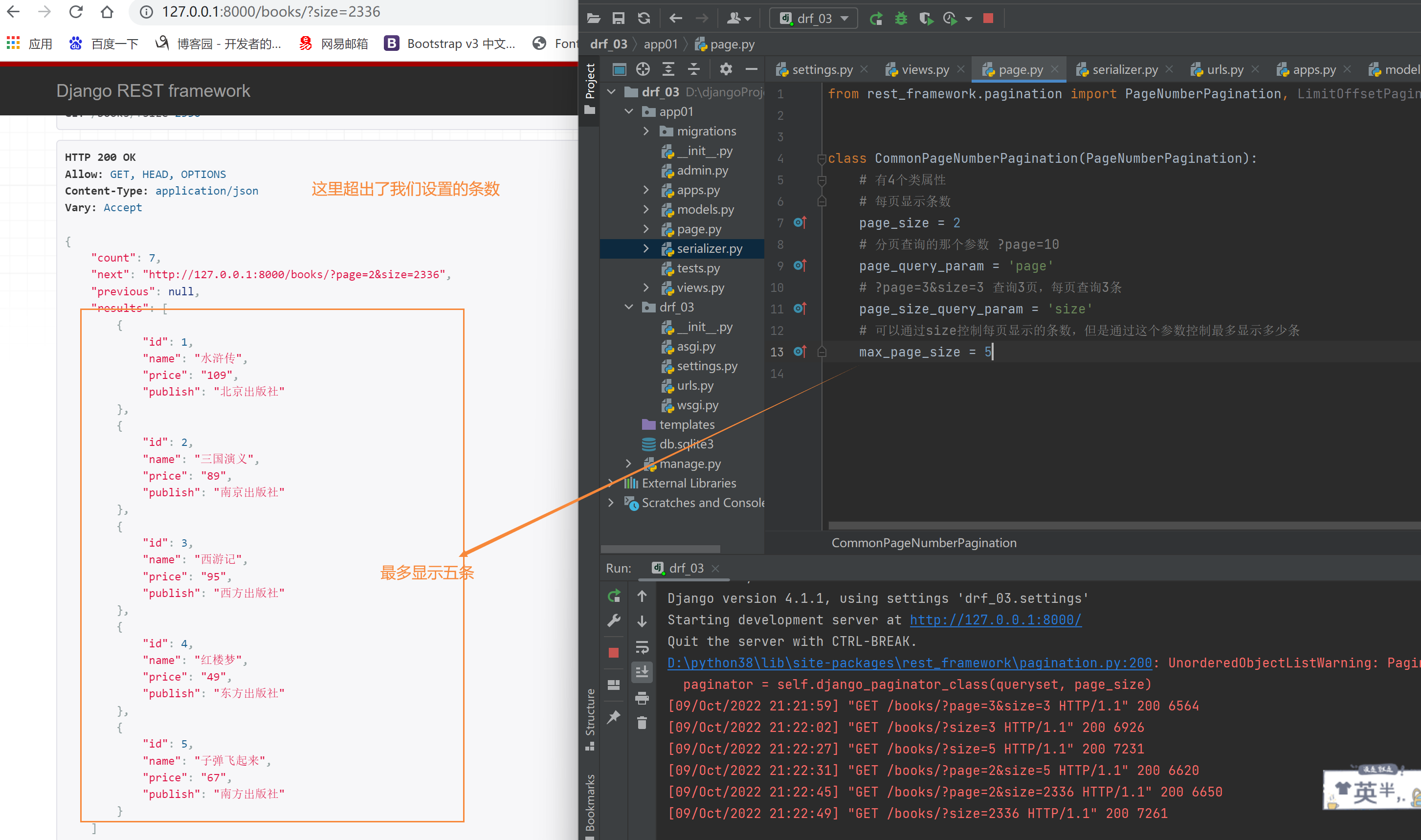
方式二:偏移分页:可以直接从第几页第几个位置开始拿数据 offset=6&limit=2
page.py
class CommonLimitOffsetPagination(LimitOffsetPagination):
# 每页显示多少条
default_limit = 2
# 可以直接从第几页第几个位置开始拿数据 offset=6&limit=2
limit_query_param = 'limit' # 取多少条
# 从第0个位置偏移多少开始取数据
offset_query_param = 'offset'
# 最大限制条数
max_limit = 5
view.py
from .page import CommonLimitOffsetPagination
class BookView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = CommonLimitOffsetPagination
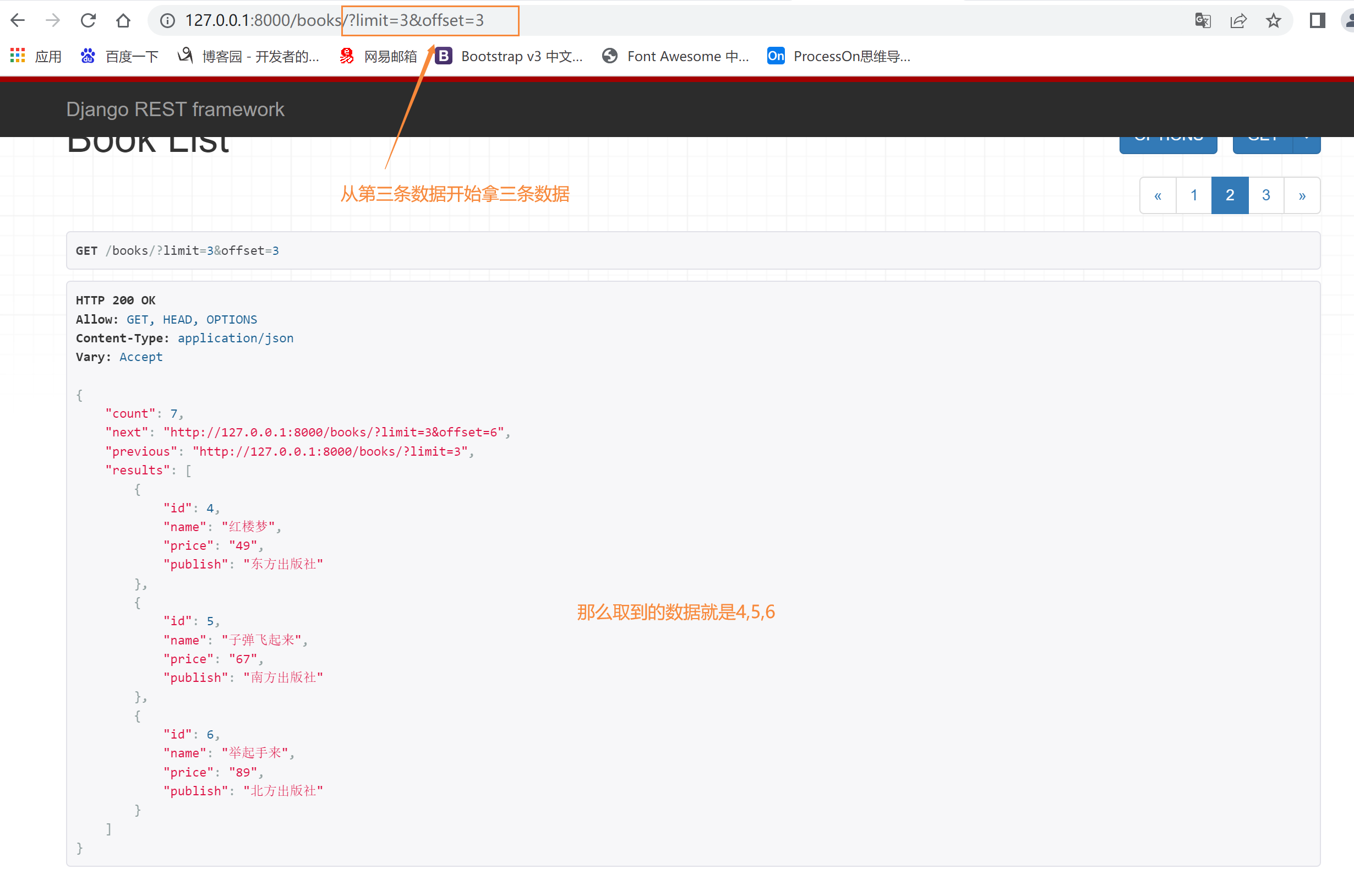
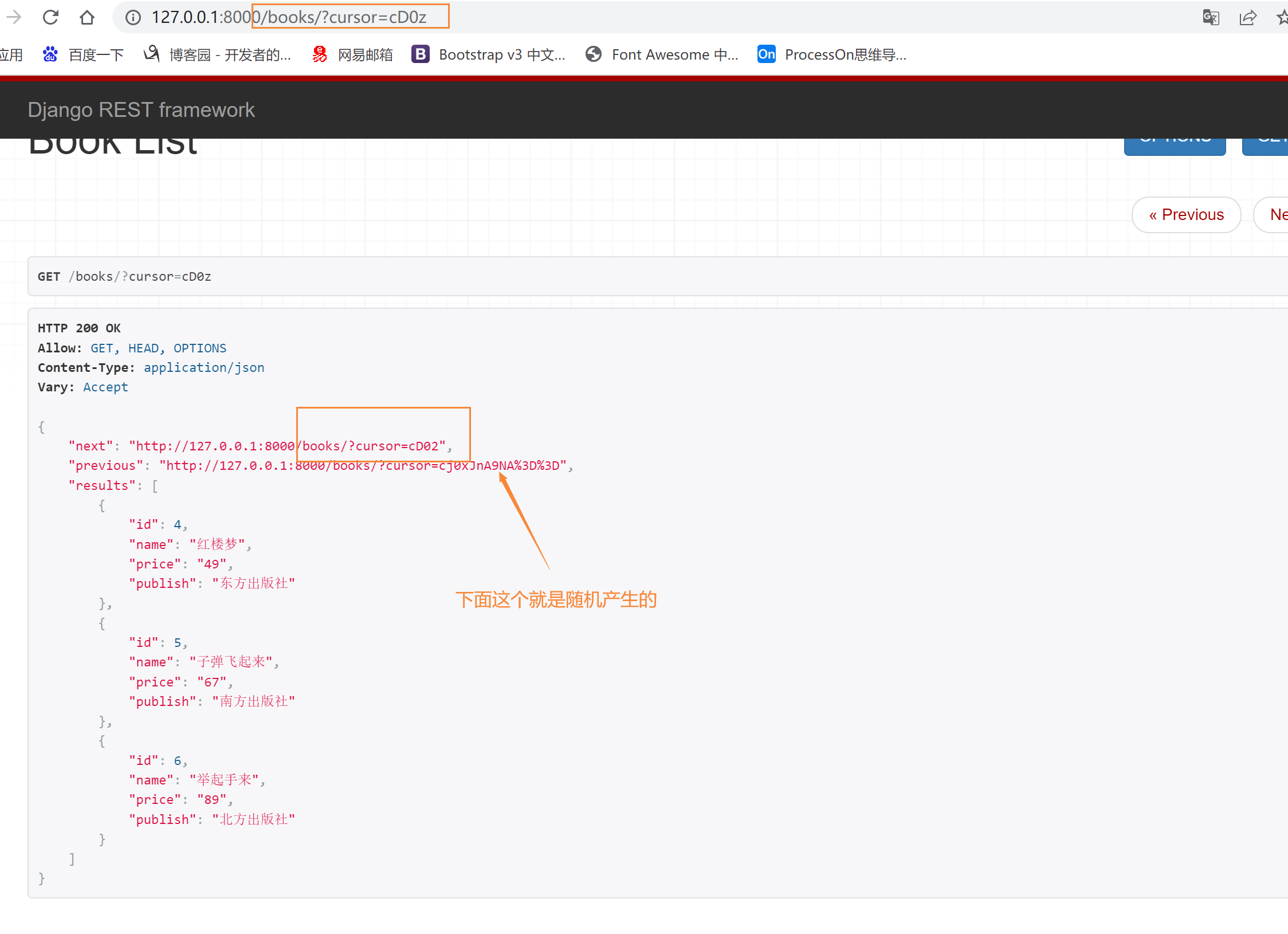
方式三:游标分页式分页
效率高,但是可控性差,只能选择上一页与下一页,不能直接跳转到某一页,这种针对于大数据
page.py
class CommonCursorPagination(CursorPagination):
# 查询的名字
cursor_query_param = 'cursor'
# 每页显示多少条
page_size = 3
# 必须是表中有的字段,一般用id
ordering = 'id'
view.py
from .page import CommonCursorPagination
class BookView(ViewSetMixin, GenericAPIView, ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = CommonCursorPagination
如果使用APIView或者GenericAPIView分页
# 如果使用APIView分页
class BookView(APIView):
def get(self,request,*args,**kwargs):
book_list=models.Book.objects.all()
# 1.实例化得到一个分页器对象,MyPageNumberPagination这个是我们自己写好的分页器类
page_cursor=MyPageNumberPagination()
# 2.使用分页器对象的paginate_queryset方法,该方法内传入queryset、request和当前视图类参数,注意返回值其实是一个新的queryset,替代了book_list
book_list=page_cursor.paginate_queryset(book_list,request,view=self)
# 3.分页器对象的get_next_link和get_previous_link是取到下一页和上一页的url,然后可以返回给前端(就是将next_url放在下面的Response里返回,前端页面就可以显示出来上下页的url了
next_url =page_cursor.get_next_link()
pr_url=page_cursor.get_previous_link()
# print(next_url)
# print(pr_url)
book_ser=BookModelSerializer(book_list,many=True)
return Response(data=book_ser.data)
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:rest_framework中的分页功能 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 