


引言
大家好,我是蜡笔小曦。
我们在通过程序向某个网页发起请求时,实际上是模拟浏览器进行http(超文本传输协议)请求,这就要求我们需要按照固定的格式进行代码构造。
一般请求数据分为三部分:请求行、请求头、请求体,如果每次都手动进行这些内容的构造,无疑会花费大量的时间,准确性也难以保证。
现在就给大家带来快速构造Python爬虫请求的高效方法,需要用到一个网站curlconverter。
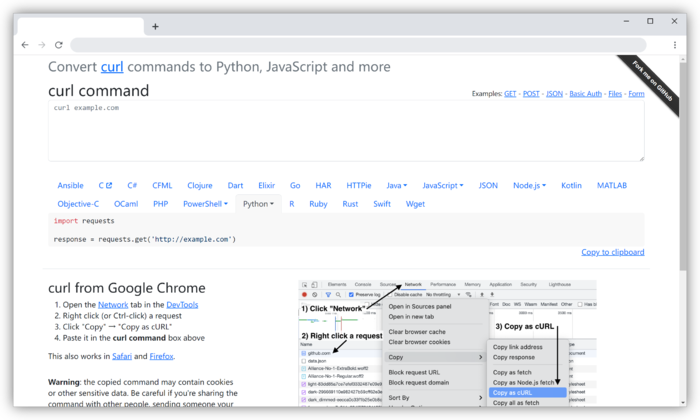
如何使用
以下步骤在Chrome浏览器中操作
- 将所要请求的网页的cURL复制下来,具体步骤见下图
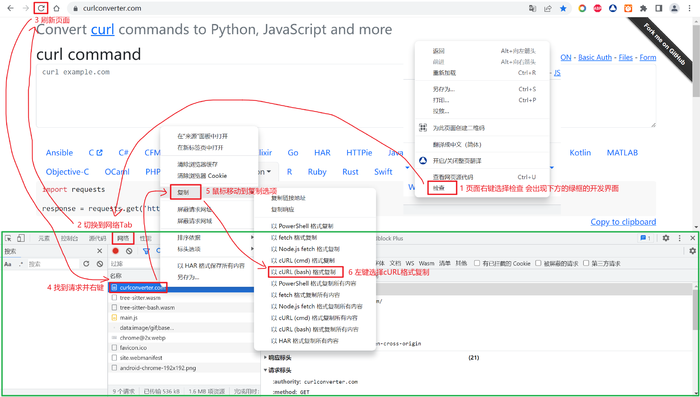
- 将上一步复制的cURL粘贴到curlconverter中,选择要转化的编程语言,网站会自动的生成Python代码,具体步骤见下图
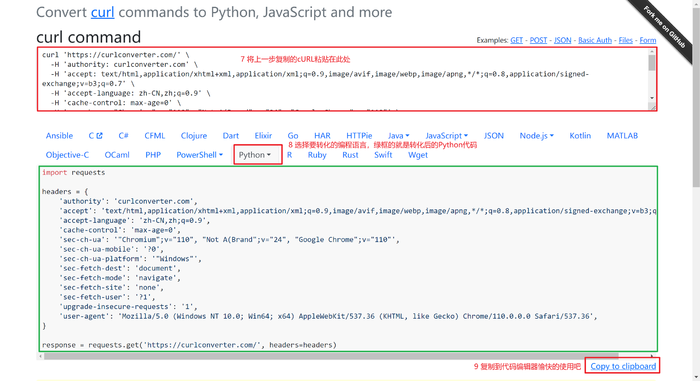
唉呀妈呀,真香!
总结
以上就是curlconverter的使用方法,尤其是面对一些复杂请求时,能极大地提升我们的开发效率,大家如果有更好的工具,欢迎评论区留言。
我是蜡笔小曦,感谢你的耐心阅读。更多精彩内容请关注公众号:蜡笔小曦爱学习。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:快速构造Python爬虫请求,有这个网站就够了! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 