AI 绘画新手魔导士在刚开始玩 Stable Diffusion 时总会遇到各种新的概念,让人困惑,其中就包括各种模型和他们之间的关系。
魔法师入门得先认识各种法师装备(各种模型),让我们遇到问题知道使用何种装备来协助自己发挥更大的效果。
safetensors
在了解各种模型之前,有必须先了解下 safetensors,玩过的应该都认识,就是很多模型的后缀。然而各种模型的后缀五花八门,但是总是能看到 safetensors 的影子,让人有些缭乱。
其实主要是因为 safetensors 支持各种 AI 模型,而在 safetensors 出现前,各种 AI 模型都有着自己独特的后缀。这就导致每种模型既可以使用 safetensors 又可以使用自己原有的后缀,所以入门的时候就会让人有点分不清。
其实 safetensors 是由 huggingface 研发的一种开源的模型格式,它有几种优势:
- 足够安全,可以防止 DOS 攻击
- 加载迅速
- 支持懒加载
- 通用性强
所以现在大部分的开源模型都会提供 safetensors 格式。
开源地址: https://github.com/huggingface/safetensors
模型分类
说完了 safetensors 我们进入正题,聊一聊在 Stable Diffusion 中常见的各种模型。
Checkpoint | Stable Diffusion
Checkpoint 是 Stable Diffusion 中最重要的模型,也是主模型,几乎所有的操作都要依托于主模型进行。而所有的主模型都是基于 Stable Diffusion 模型训练而来,所以有时会被称为 Stable Diffusion 模型。
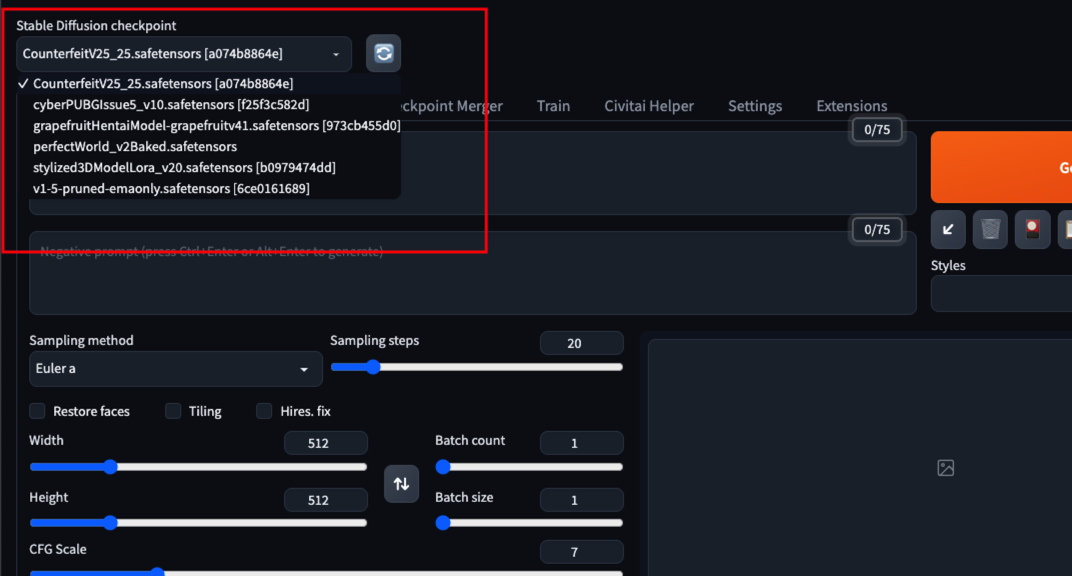
主模型后缀一般为 .ckpt 或者 .safetensors,并且体积比较庞大,一般在 2G - 7G 之间。而要管理模型我们需要进入 WebUI 目录下的 models/Stable-diffusion 目录下。
在使用 WebUI 时左上角切换的就是主模型了。

LoRA 和 LyCORIS
LoRA 是除了主模型外最常用的模型。LoRA 和 LyCORIS 都属于微调模型,一般用于控制画风、控制生成的角色、控制角色的姿势等等。
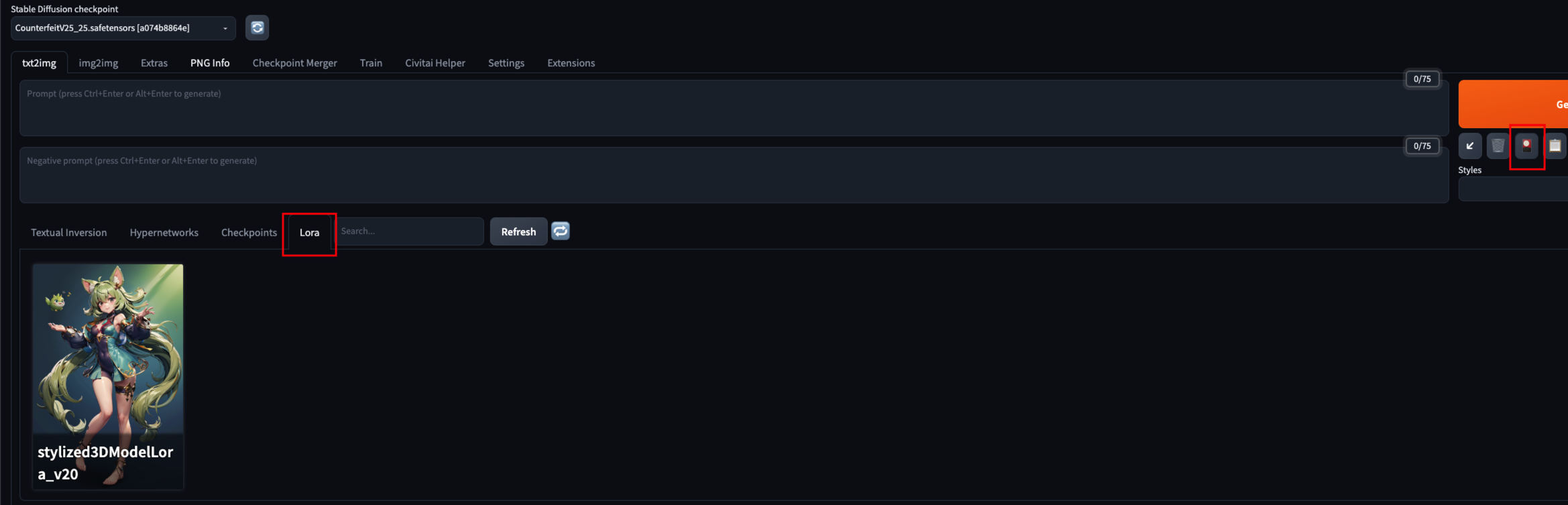
LoRA 和 LyCORIS 的后缀均为 .safetensors,体积较主模型要小得多,一般在 4M - 300M 之间。一般使用 LoRA 模型较多,而 LyCORIS 与 LoRA 相比可调节范围更大,但是需要额外的扩展才可使用。需要管理模型时我们可以进入 WebUI 目录下的 models/LoRA 目录下。
在 WebUI 中使用时,可通过点击左侧的小红灯,然后在 LoRA 菜单中点击使用。也可以直接使用 Prompt 调用。
Textual Inversion
Textual Inversion 是文本编码器模型,用于改变文字向量。可以将其理解为一组 Prompt。
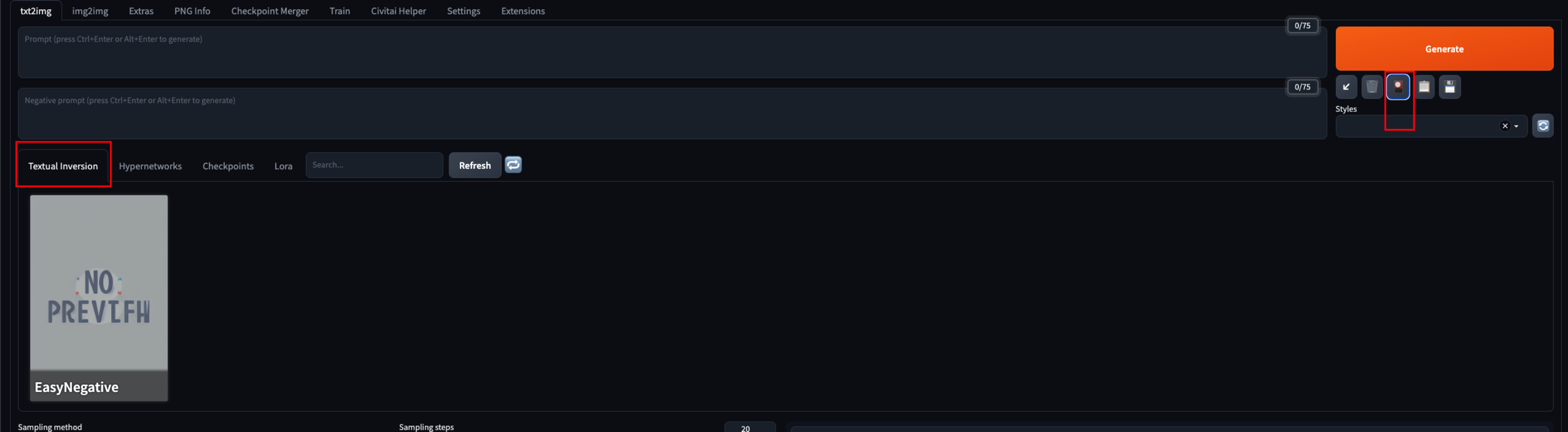
Textual Inversion 后缀为 .pt 或者 .safetensors,体积非常小,一般只有几 kb。模型所在的目录不在 models 下,而是在 WebUI 中的 embeddings 目录下。
在使用时同样可以使用小红灯中的 Textual Inversion,也可以使用 Prompt 调用。
Hypernetworks
Hypernetworks 模型用于调整模型神经网络权重,进行风格的微调。
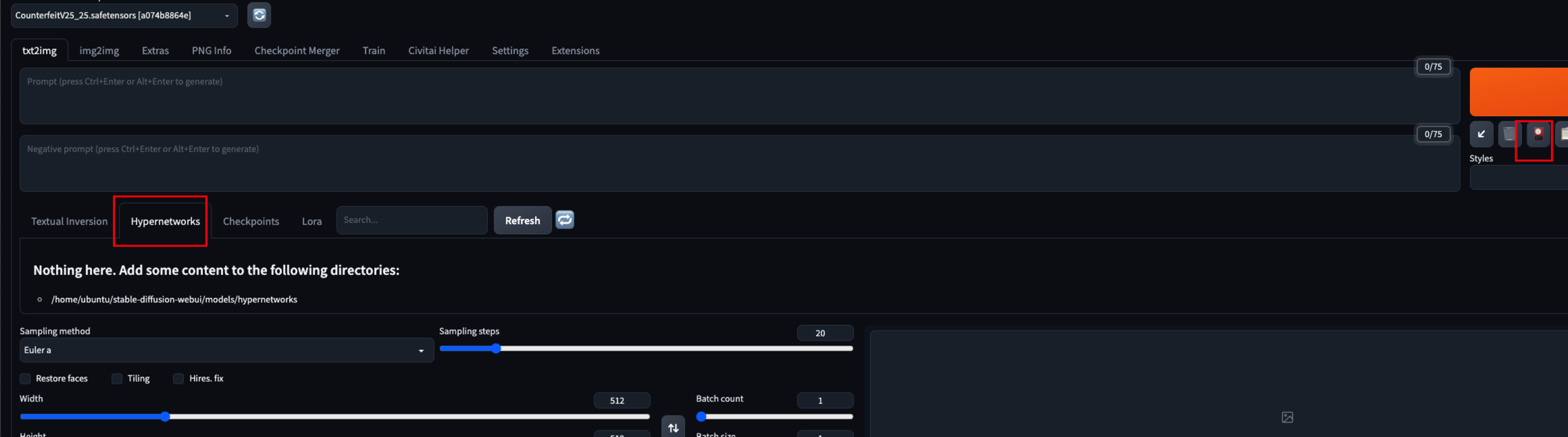
Hypernetworks 的后缀为 .pt 或者 .safetensors,体积一般在 20M - 200M 之间。模型的目录为 WebUI 下的 models/hypernetworks。
在使用时同样可以使用小红灯中的 Hypernetworks。
ControlNet
ControlNet 是一个及其强大的控制模型,它可以做到画面控制、动作控制、色深控制、色彩控制等等。使用时需要安装相应的扩展才可。
ControlNet 类模型的后缀为 .safetensors。模型的目录为 models/ControlNet。
使用时我们需要先去 Extensions 页面搜索 ControlNet 扩展,然后 Install 并 Reload UI。然后便可以在 txt2img 和 img2img 菜单下找到:
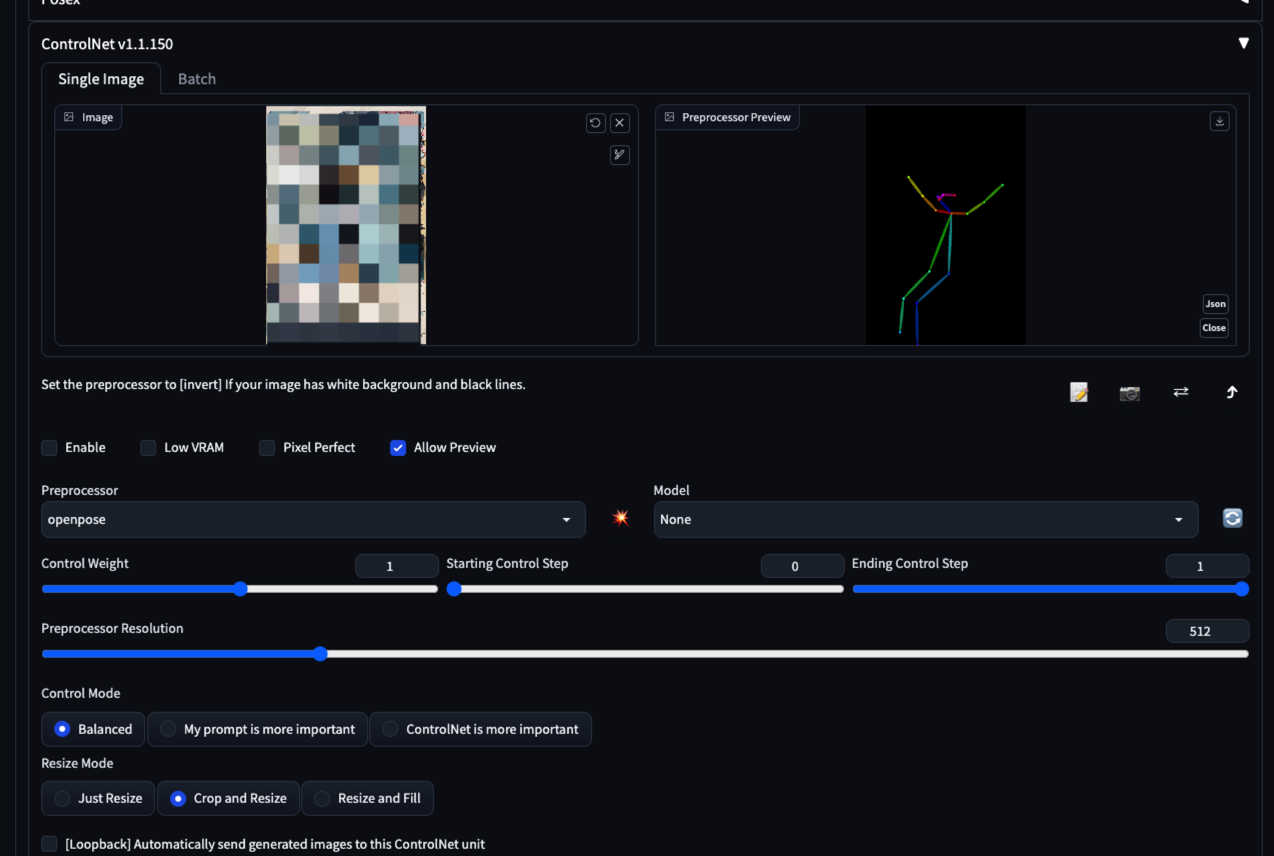
ControlNet 功能非常强大,还解决 AI 画手的噩梦问题。
VAE
VAE 模型一般用于图片亮度和饱和度的修正、画面较正和以及补光等。一般在绘图时如果出现图片亮度过低、发灰等问题时就需要用到。
VAE 模型的后缀为 .pt 或 .safetensors,体积一般为 335M 或 823M。模型的目录为 models/VAE。
使用时需要到 Settings 页面找到 SD VAE 菜单切换。

但是这样使用过于繁琐,所以如果使用到建议在 Quicksettings list 配置中添加 sd_vae。

这样就可以在 WebUI 的顶部进行切换。

CodeFormer
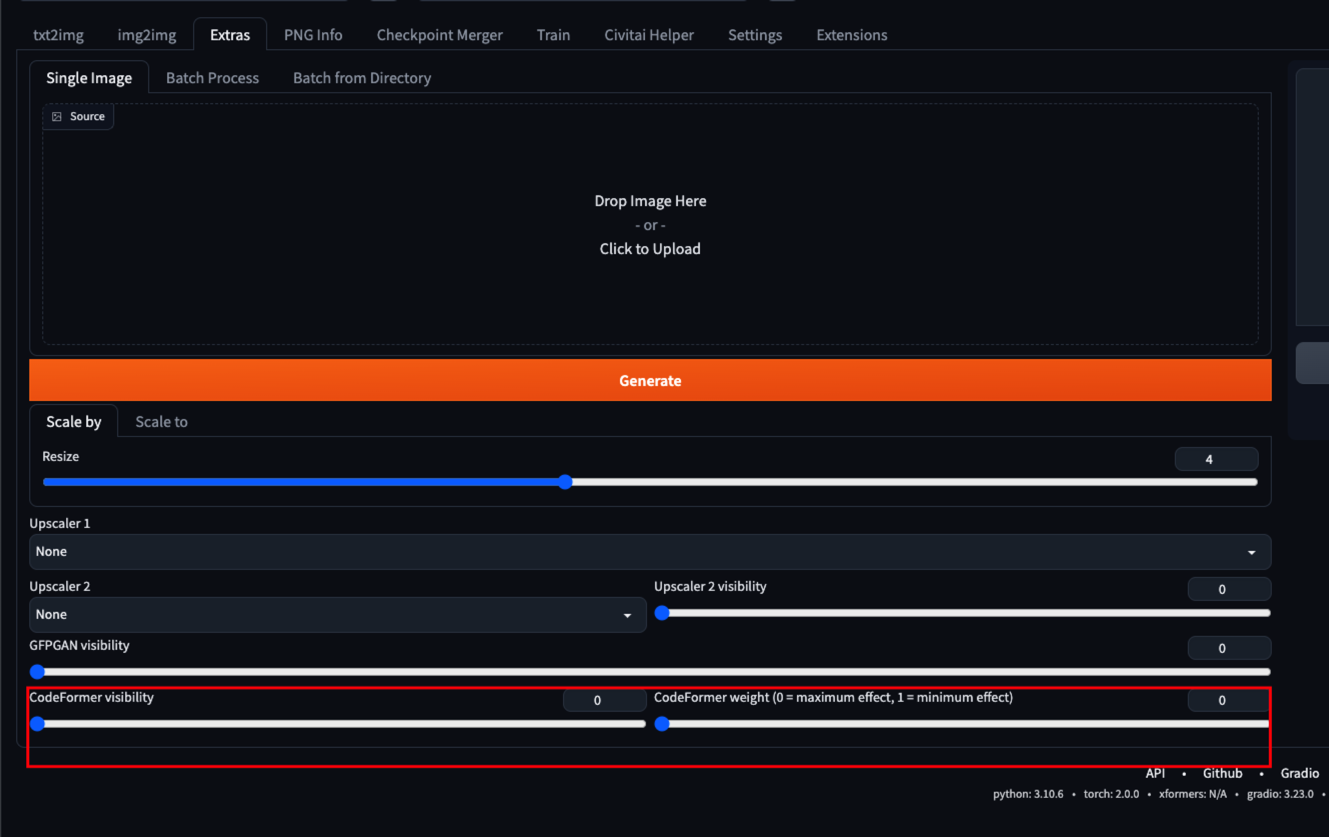
CodeFormer 模型一般用于图片的修复,比如提高图片的分辨率、将黑白照片修改成彩色照片、人脸修复等等。
CodeFormer 是一个开源项目,在 WebUI 中已经默认被整合,可以在 Extras 菜单中使用。如果需要修改 CodeFormer 版本可以将模型放到 models/codeformer
一览表
| 模型名称 | 作用 | 后缀名 | 大小 | 在 WebUI 中的文件夹 |
|---|---|---|---|---|
| Checkpoint | 主模型 | .ckpt 或 .safetensors | 2G - 7G | models/Stable-diffusion |
| LoRA 和 LyCORIS | 微调模型,一般用于控制画风、控制生成的角色、控制角色的姿势等等 | .safetensors | 2G - 7G | models/Stable-diffusion |
| Textual Inversion | 文本编码器模型 | .pt 或 .safetensors | KB 级别 | embeddings |
| Hypernetworks | 调整模型神经网络权重,进行风格的微调 | .pt 或 .safetensors | 20M - 200M | models/hypernetworks |
| ControlNet | 强大的控制模型,可以进行画面控制、动作控制、色深控制、色彩控制等等 | .safetensors | KB 级别 | models/ControlNet |
| VAE | 图片亮度和饱和度的修正、画面较正和以及补光等 | .pt 或 .safetensors | 335M 或 823M | models/VAE |
| CodeFormer | 修复模型,修复人脸、提高分辨率等 | - | - | models/codeformer |
最后
上面几种模型就是 Stable Diffusion 中最常用的几种,通过 Checkpoint 控制图片的主要风格;通过 VAE 给图片补光、调亮;通过 LoRA | LyCORIS 对模型进行风格、角色控制;通过 Textual Inversion 简化 Prompt;通过 ControlNet 进行姿势、色彩控制,修复手部。
不过这并不是 Stable Diffusion 中所有的模型,其它的一些模型如果有空再整理下。
原文链接:https://www.cnblogs.com/zxbing0066/p/17386939.html
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:AI 绘画基础 – 细数 Stable Diffusion 中的各种常用模型 【? 魔导士装备图鉴】 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 