一、if语句
if 语句让你能够检查程序的当前状态,并据此采取相应的措施。if语句可应用于列表,以另一种方式处理列表中的大多数元素,以及特定值的元素
1、简单示例
names=['xiaozhan','caiyilin','zhoushen','DAOlang','huangxiaoming'] for name in names: if name == 'caiyilin': #注意:双等号'=='解读为“变量name的值是否为'caiyilin' print(name.upper()) else: print(name.title())
每条if语句的核心都是一个值为 True 或 False 的表达式,这种表达式被称为条件测试(如上述条件 name == 'caiyilin'),根据条件测试的值为 True 还是 False 来决定是否执行 if 语句中的代码。如果条件测试的值为True ,Python就执行紧跟在 if 语句后面的代码;如果为 False , Python 就忽略这些代码,不执行。
在Python中检查是否相等时区分大小写,例如,两个大小写不同的值会被视为不相等
my_fav_name = 'daolang' for name in names: if name == my_fav_name: print('Yes') print('No') print('n') for name in names: if name.lower() == my_fav_name: print('Yes') print('No') print('n') #下方使用 if……else语句 for name in names: if name.lower() != my_fav_name: #检查是否不相等 print('NO') else: print('YES')
查多个条件:有时候需要两多个条件都为True时才执行操作;或者多个条件中,只满足一个条件为True时就执行操作,在这些情况下,可分别使用关键字and和or
ages=['73','12','60','1','10','55','13'] for age in ages: if age > str(60): #注意:ages中为列表字符串,所以age也是字符串,无法与整型的数字相比,需要先将数字转化为字符串再比较。 print("The "+str(age)+" years has retired!") elif age > str(18) and age<=str(60): #两个条件都为True时 print("The "+str(age)+" years is an Adult!") elif age > str(12): print("The "+str(age)+" years is a student!") else: print("The "+str(age)+" years is a child!")
二、while语句
for 循环用于针对集合中的每个元素都一个代码块,而 while 循环不断地运行,直到指定的条件不满足为止。
例如,while 循环来数数
current_number = 1 while current_number <= 5: print(current_number) current_number += 1 print("n") print(current_number)
当x<=5时,x自动加1,直到大于5时(也即current_number=6),退出while循环,再执行print(current_number)语句。
运行结果:
1 2 3 4 5 6
1、可以用来定义一个标志
定义一个变量,用于判断整个程序是否处于活动状态。这个变量被称为标志,相当于汽车的钥匙,钥匙启动时,汽车所有的电子设备、发动机、空调等均可正常运行,一旦钥匙关闭时,整个汽车熄火状态,全部不能运行。
同理,程序在标志为 True 时继续运行,并在任何事件导致标志的值为 False 时让程序停止运行。
prompt = "nTell me your secret, and I will repeat it back to you:" prompt += "nEnter 'quit' to end the program. " active = True #定义一个标志 while active: #当active为真的时候,执行程序, message = input(prompt) if message == 'quit': #当输入信息为quit时,标志active为False,程序停止 active = False else: print(message)
2、使用 break 退出循环,要立即退出 while 循环,不再运行循环中余下的代码
prompt = "nPlease enter the name of a city you have visited:" prompt += "n(Enter 'quit' when you are finished.) " while True: city = input(prompt) if city == 'quit': break else: print("I'd love to go to " + city.title() + "!")
3、在循环中使用 continue
current_number = 0 while current_number < 10: current_number += 1 #以1逐步增加 if current_number % 2 == 0: #求模运行,是2的倍数,为0 continue #忽略并继续运行。 print(current_number) #打印出数字
4、使用 while 循环来处理列表和字典
1)处理列表中的数据
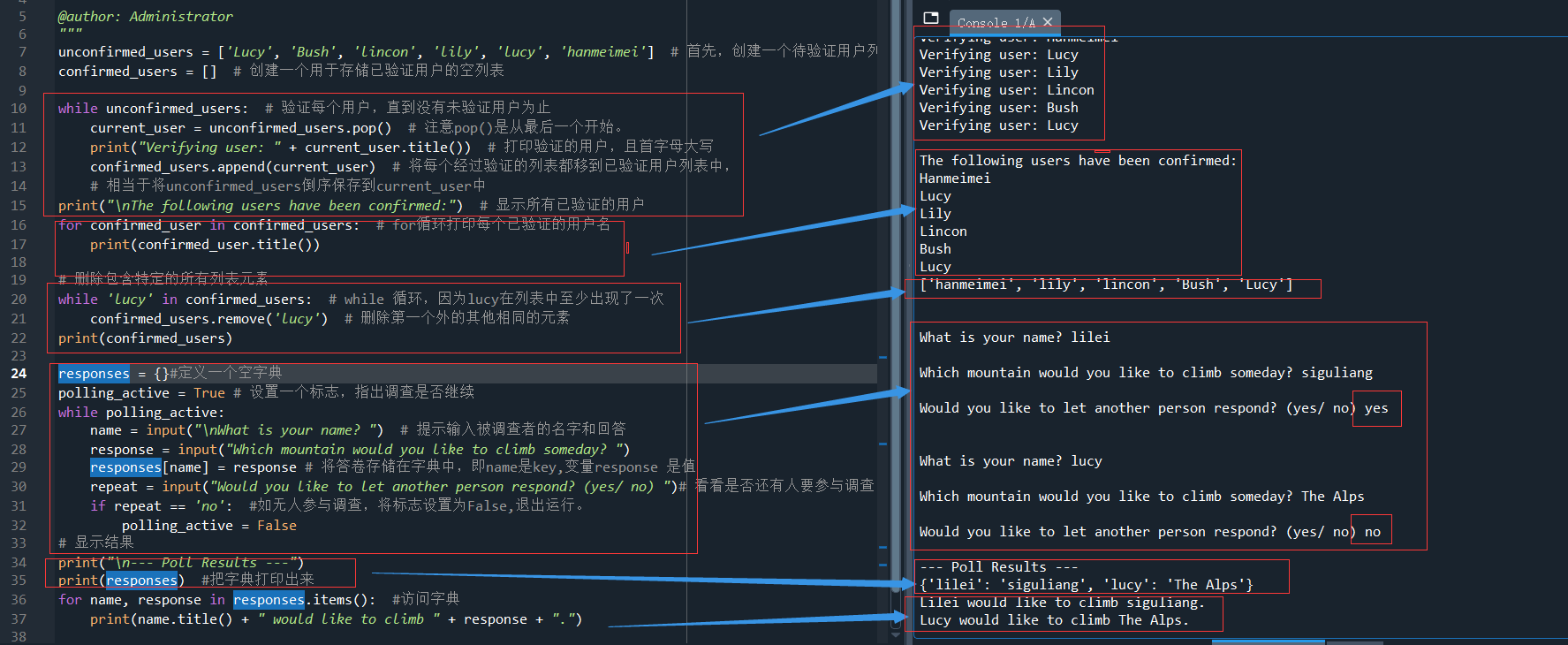
unconfirmed_users = ['Lucy', 'Bush', 'lincon', 'lucy', 'jack', 'lily', 'lucy', 'hanmeimei'] # 首先,创建一个待验证用户列表 confirmed_users = [] # 创建一个用于存储已验证用户的空列表 while unconfirmed_users: # 验证每个用户,直到没有未验证用户为止 current_user = unconfirmed_users.pop() # 注意pop()是从最后一个开始。 print("Verifying user: " + current_user.title()) # 打印验证的用户,且首字母大写 confirmed_users.append(current_user) # 将每个经过验证的列表都移到已验证用户列表中, # 相当于将unconfirmed_users倒序保存到current_user中 print("nThe following users have been confirmed:") # 显示所有已验证的用户 for confirmed_user in confirmed_users: # for循环打印每个已验证的用户名 print(confirmed_user.title()) print("n") # 删除包含特定的所有列表元素 while 'lucy' in confirmed_users: # while 循环,因为lucy在列表中至少出现了一次 confirmed_users.remove('lucy') # 删除除最后一个外的其他相同的元素 print(confirmed_users)
运行结果如下:
Verifying user: Hanmeimei
Verifying user: Lucy
Verifying user: Lily
Verifying user: Jack
Verifying user: Lucy
Verifying user: Lincon
Verifying user: Bush
Verifying user: Lucy
The following users have been confirmed:
Hanmeimei
Lucy
Lily
Jack
Lucy
Lincon
Bush
Lucy
['hanmeimei', 'lily', 'jack', 'lincon', 'Bush', 'Lucy']#注意保留的是最后一个Lucy
2) 处理字典中的数据
responses = {}#定义一个空字典
polling_active = True # 设置一个标志,指出调查是否继续
while polling_active:
name = input("nWhat is your name? ") # 提示输入被调查者的名字和回答
response = input("Which mountain would you like to climb someday? ")
responses[name] = response # 将答卷存储在字典中,即name是key,变量response 是值
repeat = input("Would you like to let another person respond? (yes/ no) ")# 看看是否还有人要参与调查
if repeat == 'no': #如无人参与调查,将标志设置为False,退出运行。
polling_active = False
# 调查结束,显示结果
print("n--- Poll Results ---")
print(responses) #把字典打印出来
for name, response in responses.items(): #访问字典
print(name.title() + " would like to climb " + response + ".")
运行结果:
What is your name? lilei
Which mountain would you like to climb someday? siguliang
Would you like to let another person respond? (yes/ no) yes
What is your name? Lucy
Which mountain would you like to climb someday? The Alps
Would you like to let another person respond? (yes/ no) no
--- Poll Results ---
{'lilei': 'siguliang', 'Lucy': 'The Alps'}
Lilei would like to climb siguliang.
Lucy would like to climb The Alps.
实际运行:(为显示全,已删除部分unconfirmed_users中的名字)

本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python入门基础(6)–语句基础(if语句、while语句) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 