前言
最近在学习人脸的目标检测任务时,用了Haar人脸检测算法,这个算法实现起来太简洁了,读入个.xml,调用函数就能用。但是深入了解我发现这个算法原理很复杂,也很优秀。究其根源,于是我找了好些篇相关论文,主要读了2001年Paul Viola和Michael Jones在CVPR上发表的一篇可以说是震惊了计算机视觉的文章,《Rapid Objection Dection using a Boosted Cascade of Simple Features》。这个算法最大的特点就是快!在当时,它能够做到实时演示人脸检测效果,这在当时的硬件情况下是非常震惊的,且还具有极高的准确率。同时在2011年,这篇论文在科罗多拉的会议上获得了“十年内影响最为深远的一篇文章”。在我们知道这篇文章有多么的NB之后,接下来我们来细细的品味这篇文章的技术细节。
根据论文Abstract描述,该论文主要有三个巨大贡献:
- 第一个贡献是引入了“积分图”的图像表示方法,它能够加快检测时的计算速度;
- 第二个贡献是提出了一个基于AdaBoost的学习算法,它能够从大量的数据中提取少量且有效的特征来学习一个高效的分类器;
- 第三个贡献是提出了注意力级联的算法,它能够让分类器更多聚焦于object-like区别,而不是与被检测目标无关的背景图像等区域,也是极大的加快了目标检测速度。
总结起来就是,Haar级联算法实际上是使用了boosting算法中的AdaBoost算法,Harr分类器用AdaBoost算法构建了一个强分类器进行级联,而再底层特征特区上采用的是更加高效的矩形特征以及积分图方法,即:
Haar分类器 = Haar-like特征 + 积分图法 + AdaBoost算法 + 级联
1. Haar-like特征提取
注意:由于原论文中对于Haar-like特征的描述过少,很多细节不完整,这部分将会详细介绍论文中没有讲的算法细节。
1.1 基本Haar特征
Haar-like是一种非常经典的特征提取算法,尤其是它与AdaBoost组合使用时对人脸检测有着非常不错的效果。虽然一般提及到Haar-like的时候,都会和AdaBoost、级联分类器、人脸检测、积分图一起出现,但是Haar-like本质上只是一种特征提取算法。它涉及到了三篇经典论文,尤其是第三篇论文,让它快速发展。
最原始的Haar-like特征是在《A general framework for object detection》中提出的,它定义了四个基本特征结构,如下图所示:
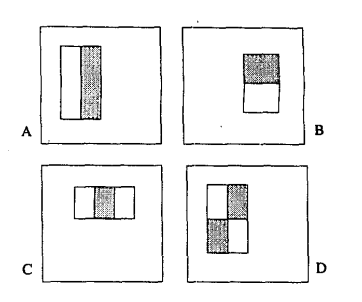

可以将这个它们理解成为一个窗口,这个窗口将在图像中做步长为1的滑动,最终遍历整个图像。它的整体遍历过程是:当一次遍历结束后,窗口将在宽度或长度上,窗口将在宽度或长度上成比例的放大,再重新之前遍历的步骤,直到放大到最后一个比例后结束(放大的最大比例一般是与原图像相同大小比例)。
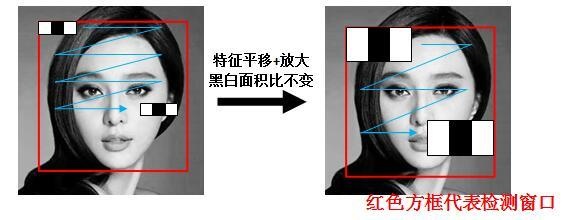
例子:以x3特征为例,在放大+平移过程中白:黑:白面积比始终是1:1:1。首先在红框所示的检测窗口中生成大小为3个像素的最小x3特征;之后分别沿着x和y平移产生了在检测窗口中不同位置的大量最小3像素x3特征;然后把最小x3特征分别沿着x和y放大,再平移,又产生了一系列大一点x3特征;然后继续放大+平移,重复此过程,直到放大后的x3和检测窗口一样大。这样x3就产生了完整的x3系列特征。
同样,通过我们上文中关于Haar-like特征的遍历过程可知,Haar特征可以在检测窗口中由放大+平移产生(黑:白区域面积比始终保持不变)。那么这些通过放大 + 平移的子特征总共有多少个呢?Rainer Lienhart在他的论文中给出了解释:假设检测窗口大小为(W*H),矩阵特征大小为(w*h),X和Y为表示矩形特征在水平和垂直方向能放大的最大比例系数:
Y = [frac{H}{h}]
]
其中(W)和(H)是整个图像的宽高,(w)和(h)是Harr窗口的初始宽高,可以放大的倍数为(X·Y)。
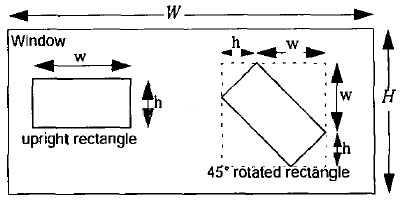
根据以上,在检测窗口Window中,一般矩形特征(upright rectangle)的数量为:
]
以x3的特征(即特征大小的pixel为1x3)为例来解释这个公式:
- 特征框竖直放大1倍,即无放大,竖直方向有(H-h+1)个特征
- 特征框竖直放大2倍,竖直方向有(H - 2h + 1)个特征
- 特征框竖直放大3倍,竖直方向有(H - 3h + 1)个特征
- 如此到竖直放大Y = floor(H/h)倍,竖直方向有1个特征,即(H-Y*h+1)
那么竖直方向总共有:
(H - h + 1) + (H - 2h + 1) + (H - 3h + 1) + ...... + (H - Y*h + 1) = Y[H + 1 - h(1 + Y)/2]个特征。水平方向同理可得。
考虑到水平和竖直方向缩放是独立的,当x3特征在24*24大小的检测窗口时,此时(W=H=24,w=3,h=1,X=8,Y=24),一共能产生27600个子特征。
1.2 扩展Haar特征
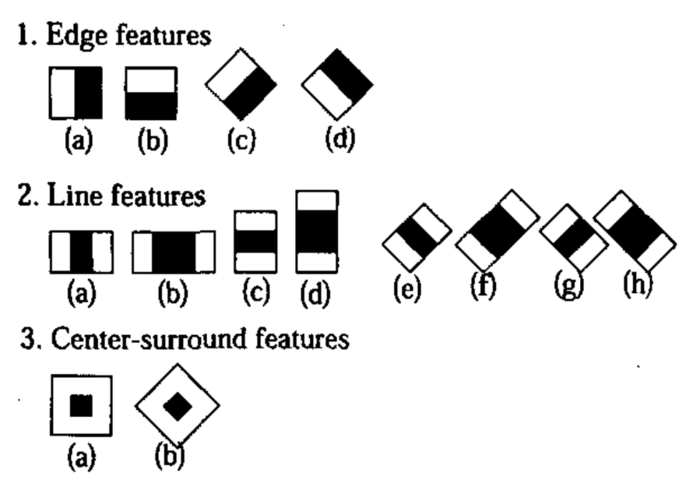
在基本的四个Haar特征基础上,文章《An entended set of Haar-like features for rapid objection detection》将原来的4个特征拓展为14个。这些拓展特征主要增加了旋转性,能够提取到更丰富的边缘信息。比如:如果一张要检测的人脸不是人脸,是一张侧脸的时候,此时基本的四个Haar特征就没法对其进行有效的特征提取,于是其提出了以下拓展的Haar-like特征:
1.3 Haar特征值的计算
关于Haar特征的计算,按照Opencv代码,Haar特征值 = 整个Haar区域像素和 x 权重 + 黑色区域内像素和 x 权重。
]
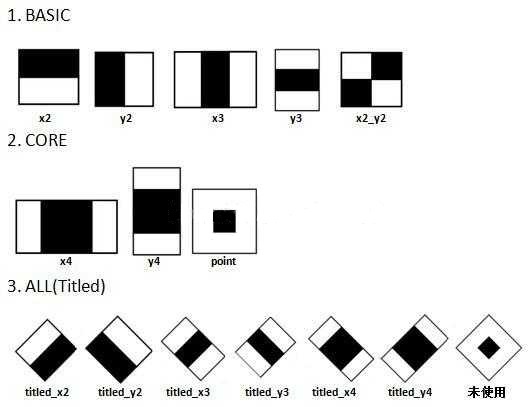
比如上图中的x3和y3特征,其(weight_{all}=1,weight_{black}=-3),上图中的(point)特征,(weight_{all}=1,weight_{black}=-9);其余11种特征均为(weight_{all}=1,weight_{black}=-2)。
所以,对于x2特征的特征值 = (黑 + 白) * 1 + 黑 * (-2) = 白 - 黑,对于Point特征值 = (黑 + 白) * 1 + 黑 (-9) = 白 - 8 * 黑。这个就是很多文章种所提到的”特征值=白色区域像素和减去黑色区域像素和”。
为什么要这样设置这种加权相减呢?由于有些特征它的黑白面积不相等,有的特征黑白面积相等,设置权值可以抵消黑白面积不等而带来的影响,保证所有Haar特征的特征值在灰度分布绝对均匀的图中为0(比如图像所有像素相等,那么它的特征值就会是0)。
接下来我们再对特征值的含义进行一个解释。以MIT人脸库中2706个大小为20*20的人脸正样本图像为数据,计算下图中位置的Haar特征值,结果如图所示:
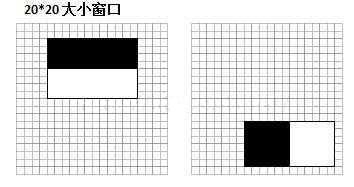
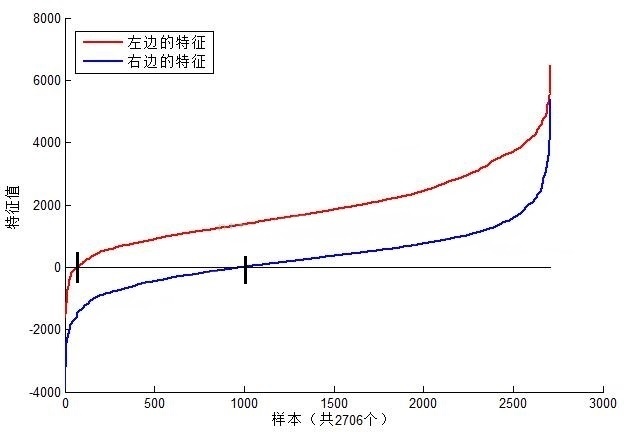
上图中左边特征结果为红色,右边为蓝色。可以看到,2个不同的Haar特征在同一组样本中具有不同的特征值分布,左边特征计算出的特征值基本都大于0,而右边特征的特征值基本均匀分布于0两侧(分布越均匀对样本的区分度越小)。正是由于样本中Haar特征值分布不同,导致了不同Haar特征分类效果不同。显而易见,对样本区分度越大的特征分类效果越好,即红色曲线对应的左边的Haar特征分类效果好于右边的Haar特征。同时,我们结合人脸可以知道,这个特征可以表示眼睛要比脸颊的颜色要深,因为能够很有效的进行区分。
总结之下,我们可以知道:
- 在检测窗口通过平移 + 放大可以产生一系列的Haar特征(也就是说,黑白面积比例相同,但是大小不同的特征可以算作多个特征),这些特征由于位置和大小不同,分类效果也各异。
- 通过计算Haar特征的特征值,可以有效将图像矩阵映射为1维特征值,有效实现了降维。
1.4 Haar特征的保存
在OpenCV的XML文件中,每一个Haar特征都被保存在2~3个形如:
]
的标签,其中x和y代表Haar矩形左上角坐标(以检测窗口的左上角为原点),width和height表示矩形的宽和高,weight表示权重值。
1.5 Haar特征值标准化
由上图中两个特征计算的特征值可以发现,一个1218大小的Haar特征计算出的特征值变换范围从-2000 ~ +6000,跨度非常的大。这种跨度大的特性不利于量化评定特征值,所以需要进行数据标准化来压缩特征值范围。假设当前检测窗口中的图像为i(x,y),当前检测窗口为wh大小。OpenCV中标准化步骤如下:
-
计算检测窗口中间部分(w - 2) * (h - 2)的图像灰度值和灰度值平方和
[sum = sum i(x,y), sqsum = sum i^2(x,y)
] -
计算平均值:
[mean = frac{sum}{w*h} \
sqmean = frac{sqsum}{w*h}
] -
计算标准化因子
-
[varNormFactor = sqrt{sqmean - mean^2}
] -
标准化特征值:
[normValue = frac{featureValue}{varNormFactor}
]
注意:在检测和训练时,数据标准化的方法一定要一致,否则可能由于标准化不同带来的误差导致模型无法工作。
2. 积分图计算
与Haar紧密相连的就是积分图了,它源自于这篇论文《Rapid Object Dection using a boosted cascade of simple features》,它使用积分图的方法快速计算了Haar特征。在上文中我们提到过,当x3特征在24*24大小的检测窗口(W=H=24,w=3,h=1,X=8,Y=24)滑动时,一共能产生27600个子特征。在计算这些特征值时,我们会有很多次重复且无效的计算,那么积分图的提出就是为了让其计算的更加高效。积分图只需要遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大提高了图像特征值计算的效率。
积分图主要的思想是将图像从起点开始到各个点所形成的矩形区域像素之和作为一个数组的元素保存在内存中,当要计算某个区域的像素和时可以直接索引数组的元素,不用重新计算这个区域的像素和,从而加快了计算(这有个相应的称呼,叫做动态规划算法)。积分图能够在多种尺度下,使用相同的时间(常数时间)来计算不同的特征,因此大大提高了检测速度。
积分图是一种能够描述全局信息的矩阵表示方法。积分图的构造方式是:位置(
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:使用Harr特征的级联分类器实现目标检测 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 