生成模型——PixelRNN、PixelCNN、变分自编码器VAE和生成式对抗网络GAN
之前我们已经讲了很多的监督学习的网络模型——有数据集x和标签集y,我们找到一个函数或一种关系,可以完成从x到y的映射;而无监督学习是指,在没有标签的训练数据的情况下,学习一些数据中潜在的隐含结构;生成模型就属于无监督中的一种。
1. 什么是生成模型
通俗地讲,比如有一堆猫狗的图片,之前学过的判别模型只是要找到猫狗的差异就可以,看到图像能够判断出是什么类别;而生成模型则是通过学习猫是什么样的,狗是什么样的,它有能力生成新的一张新的猫或狗的图片;也就是说想让计算机有自己的创造力,比如让它看了很多动漫头像后,自己尝试着画出来没出现过的。
数学上比较形象地讲,判别模型是对P(y|x)进行建模,生成模型是对P(x,y)进行建模,给定具有特定密度分布的数据,想要生成同样密度分布的数据。因此,我们的目标是找到训练数据的分布函数。生成模型还可以细分,一种是能显式对P(x,y)建模的,另外一种是只能从样本中生成新的样本的。
生成模型的关键点为:
a、我们有一份数据集
b、我们假设这份数据集服从某个未知的分布Pdata
c、我们生成一个模型Pmodel去模仿分布Pdata,并用Pmodel生成一个新的观测,这个新的观测似乎是用Pdata生成的一样。
其中有两个关键规则:
规则1:新生成的观测似乎是用Pdata生成的
规则2:模型Pmodel可以稳定的生成不同于现有观测的新的观察
2. PixelRNN
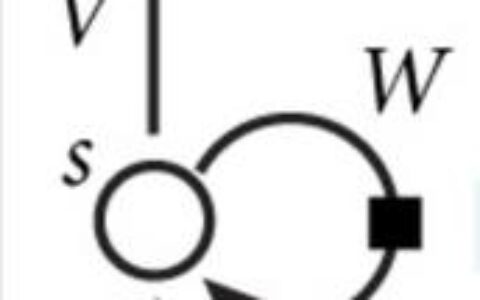
PixelRNN构建了原像素值的离散概率,并且将图像中整个的相关性进行编码。PixelRNN图像生成模型实际上是概率密度模型,由12层二维长短期记忆层(Long Short-Term Memory)组成,这些层在状态states里使用了LSTM单元,并且采用了卷积去同时计算数据里空间维度的所有状态states。模型的目的是估计原始图片的分布,并且此分布能实现计算图像的可能性和去生成一个新的图像。PixelRNN每次扫描图像的每一行和每一行内的每一个像素。对于各个像素,它根据扫描的上下文来预测出可能的像素。
pixelRNN中,从左上角开始定义为“之前的像素”。我们有图像数据x,想对该图像的概率分布或者似然p(x)建模,我们使用链式法则将这一似然分解为一维分布的乘积,我们有每个像素xi的条件概率,其条件是给定所有下标小于i的像素(x1到xi-1),这时图像中所有像素的概率或联合概率就是所有这些像素点似然的乘积。
p(x)是每个图像x的概率。p(x_i|x_1,…,x_i-1)是给定所有过去像素x_1,…,x_i-1下第i个像素x_i的概率。每个像素x_i被三个值共同决定,分别来自红绿蓝通道。
因此每个像素都建立在过去所有的生成像素和其他通道的条件上。
训练这个RNN时,一次前向传播需要从左上到右下串行走一遍,然后根据上面的公式求出似然,并最大化似然以对参数做一轮更新。
3. PixelCNN
上述方法存在的问题是,在训练阶段和预测阶段,位置像素的分布律和取值需逐个构建或推断,因而计算效率不高。一个解决方法是使用CNN代替RNN来构建未知像素的分布律,这样,未知像素的取值依赖于一小块区域,而非仅是与之相关联的像素;同时,使得训练过程可以并行化,无需逐像素进行;但推断过程仍是逐像素的。下面我们来看一下具体的过程


这是一个5*5的掩膜卷积核。它的作用就是只保留中心点处之前的像素信息。
可以看到当要提取中心点的像素信息的时候,这个点的左边和前面的像素信息都得到了提取,右边和后面的像素信息被“遮盖”住了,而关于这个点的信息的提取论文中又提出了两种方式进行获取(mask A和mask B)
之前我们说过,每个像素除了由之前的生成像素决定外,还取决于RGB三个通道。按照RGB的位置顺序来说,R算是前面的信息,G属于中间的信息,B是后面的信息,所以在记录当前像素点的R通道上面的信息时就不能把后面的GB信息当作已知条件,同样的,在记录当前像素点的B通道上的信息时可以将RG两个通道上的信息当作已知条件。所以可以看到有这样的传递关系。
而mask A和mask B的区别就是,比如记录当前像素点的G通道上面的信息时,mask A只将前面的像素点和R通道上的信息算作已知信息,而mask B还要将G也算作已知信息。在pixelCNN中,只有在第一个卷积层上使用了maskA,后面所有的层上都是使用的maskB这种掩膜。
PixelCNN的盲点问题
由于在产生模型所需的 MaskCNN 时,掩住了当前像素同一行的右边像素(注意,模板中间像素为当前像素),当构建多层 MaskCNN 网络时,叠加效应使 receptive field 产生了盲点,所谓的“盲点”就是指当前的像素值信息提取的过程中无论如何都不会包括到灰色区域的像素信息。
PixelCNN在训练的时候得益于卷积可以并行运算,所以训练时间较pixelRNN有提高,但其生成效果不如 PixelRNN,这可能是因为以下原因
1)PixelRNN 在生成当前像素条件概率时,使用了所有之前所有的像素信息,而PixelCNN 受到 receptive field 的影响,只能从其中一部分相邻像素获得信息,而且还会受到 blind spot(盲点)的影响,盲点可以占到有效 receptive field 的四分之一,因而直接使用 PixelCNN 预测会受到信息不完整的影响;
2)PixelRNN 的实现单元是 LSTM 其结构复杂,有多个选择的门(gate),因而其本身就可以对更复杂的关系进行建模,因而其建模能力要优于仅使用简单的 CNN 的PixelCNN 的能力。
因此,又出现了后来的Gated PixelCNN,本文不细述。
4. 变分自编码器VAE
在此之前,我们先来了解一下什么是自编码器和变分推断。
自编码器(Autoencoder)是一种特定的神经网络结构,其目的是为了将输入信息映射到某个更低维度的空间,生成包含重要特征的编码code,这部分称为Encoder,可用函数 h=f(x) 表示,然后再利用Decoder将code重构成为尽量能还原原输入的结果,用函数 r=g(h) 。我们的目的就是尽量使 g(f(x))=x ,当然如果只是简单的将输入复制到输出是没有任何意义的,我们需要加一定的限制条件,使我们的模型学习到数据中更重要的特征。
变分推断:在概率模型中,我们常常需要近似难以计算的概率分布,在贝叶斯统计中,所有的对于未知量的推断(inference)问题可以看做是对后验概率的计算,而这一概率通常难以计算,变分推断就为我们提供了一种又快又简单的适用于大量数据的近似推断方法。
假定我们用向量x=x_1:n代表我们输入的观察量,向量z=z_1:m 代表模型中的隐藏变量,推断问题即为依据输入数据的后验条件概率分布P(z|x) 。变分法的基本思想是将这一问题转化为优化问题。首先,我们提出一族关于隐藏变量的近似概率分布 Q,我们希望从这一族分布中找到一个与真实的后验分布的KL Divergence最小的分布,即
之后,我们便可用 q*来近似代替真实的后验分布 P(z|x) 。因此变分推断将推断问题转化为了求极值的优化问题,而Q的选择决定了优化问题的难易度,变分法核心思想就是要选定这一族函数使得密度分布足够灵活可以近似P(z|x) 的分布,同时又足够简单使得我们可以进行高效的优化。(这一部分涉及到的数学知识很多,可以详细地去看一下推导)
变分编码器主要是引入了一个隐藏向量z的概念,把z作为条件,利用条件概率的公式计算相似性,如上面的自编码器一样
我们对这个网络进行训练,损失函数就是重构数据与原数据像素的差。当我们训练完成以后我们就可以认为我们的编码器学习到了提取重要特征的方法,能够很好的用隐藏特征z表示原图。这个时候我们就能抛开解码器,用编码器做一些其他的事情,比如我们希望能用隐藏特征z去生成数据x,这就是变分编码器的作用。
而为了从模型中生成新的样本,我们只需要从分布pmodel(z)中采样z,再经过解码网络得到样本x,其概率分布表示为
但是这个积分是难以计算的,其后验概率同样很难计算
所以我们就要利用变分近似来求其lower bound,而我们就是利用加码网络 q(z|x)来近似 pmodel(z|x),这里可做以下推断
其中,最后一项
因此,我们可以得到 log pmodel(x)的下限
其中第一项我们可以通过从加码网络中采样来近似,而第二项由于 q(z|x)和 pmodel(z)我们均可以选取可适的函数使其有闭合的解析形式,也是容易计算的。这两项合起来就是在变分推断中定义的evidence lower bound,简称ELBO函数,我们可以用梯度上升方法来逐渐优化它。
总的来说,VAE的理论原理比较自然,而且中间学习到的特征空间也可以用来迁移到其他的任务,但是虽然它显性的定义了概率分布,但并不是精确的求解概率分布,而是用lower bound来近似其概率分布,所以在做模型评估时不如PixelRNN和PixelCNN好,而且其生成的样本通常要更模糊些

5. 生成式对抗网络GAN
主要流程类似上面这个图。首先,有一个一代的generator,它能生成一些很差的图片,然后有一个一代的discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个discriminator就是一个二分类器,对生成的图片输出0,对真实的图片输出1。接着,开始训练出二代的generator,它能生成稍好一点的图片,能够让一代的discriminator认为这些生成的图片是真实的图片。然后会训练出一个二代的discriminator,它能准确的识别出真实的图片,和二代generator生成的图片。以此类推,会有三代,四代。。。n代的generator和discriminator,最后discriminator无法分辨生成的图片和真实图片,这个网络就拟合了。
GAN的大概是按照这个模式运行,但是其原理还是很复杂的(我没太看懂,这里就不写了)可以参照GAN背后的数学理论
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:生成模型——PixelRNN、PixelCNN、变分自编码器VAE和生成式对抗网络GAN - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫