操作系统:Windows10
Python版本:3.9.2
vosk是一个离线开源语音识别工具,它可以识别16种语言,包括中文。
这里记录下使用vosk进行中文识别的过程,以便后续查阅。
vosk地址:https://alphacephei.com/vosk/
一、使用vosk-server进行语音识别
docker方式启动vosk服务
1、获取vosk
[root@host32 ~]# docker search alphacep NAME DESCRIPTION STARS OFFICIAL AUTOMATED alphacep/kaldi-ru Russian websocket server for streaming speec… 11 alphacep/kaldi-en English websocket server for streaming speec… 10 alphacep/kaldi-vosk-server Websocket-based server for speech recognitio… 8 alphacep/kaldi-de German websocket server for streaming speech… 4 alphacep/kaldi-cn Chinese websocket server for streaming speec… 3 alphacep/kaldi-manylinux Helper image to build python modules for pypi 3 alphacep/kaldi-en-gpu Vosk GPU websocket server for fast processin… 2 alphacep/kaldi-en-in Streaming speech recognition based on Kaldi … 1 alphacep/kaldi-grpc-en Speech recognition gRPC server based on Kald… 0 alphacep/kaldi-es 0 alphacep/dockcross-linux-armv7 0 alphacep/vosk-unimrcp 0 alphacep/kaldi-fr French websocket server for streaming speech… 0 alphacep/kaldi-vosk-server-gpu Vosk GPU websocket server for fast processin… 0 alphacep/kaldi-en-spk 0 uburuntu/kaldi-vosk-server https://github.com/alphacep/vosk-server 0 gabrielbg99/kaldi ARM64 (Cortex-A72) version of https://hub.do… 0 gabrielbg99/kaldi-en ARM64 (Cortex-A72) version of https://hub.do… 0 [root@host32 ~]# docker pull alphacep/kaldi-cn
2、启动vosk
获取docker镜像:
docker pull alphacep/kaldi-cn:latest
启动服务:
docker run -d -p 2700:2700 alphacep/kaldi-cn:latest
非docker方式启动vosk服务
git clone https://github.com/alphacep/vosk-server
wget -c https://alphacephei.com/vosk/models/vosk-model-cn-0.15.zip
python asr_server.py vosk-model-cn-0.15
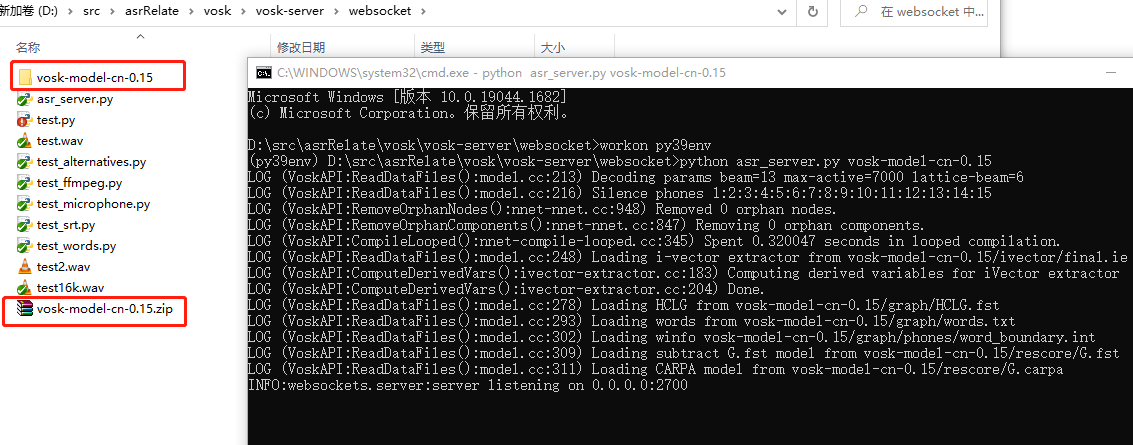
使用vosk-server测试
1、下载vosk-server源代码
命令如下:
git clone https://github.com/alphacep/vosk-server
2、测试
test2.wav内容:
自然语言理解和生成是一个多方面问题,我们对它可能也只是部分理解。
cd vosk-server/websocket
./test.py test2.wav
识别效果如下:

注意:语音文件test1.wav的格式必须8khz 16bit mono PCM(8000采样率,16位采样精度,单声道,pcm)。
可以在屏幕上看到服务器返回的识别结果,结果是json格式。
如果提示如下错误:
AttributeError: module 'asyncio' has no attribute 'run'
请使用python 3.7以上的版本。
python使用vosk-server进行中文语音识别的演示视频,可从如下途径获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 202205210101 获取。
二、使用vosk-api进行语音识别
安装vosk
命令如下:
pip install vosk
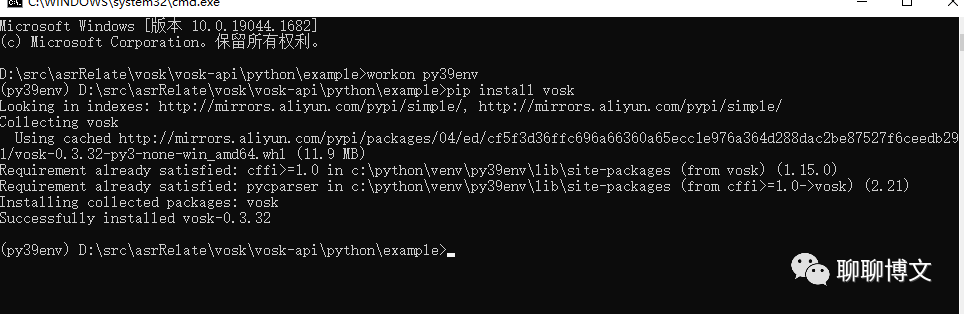
下载示例代码
获取示例代码:
git clone https://github.com/alphacep/vosk-api.git
目录结构如下:
下载预编译的模型文件
下载地址:https://alphacephei.com/vosk/models
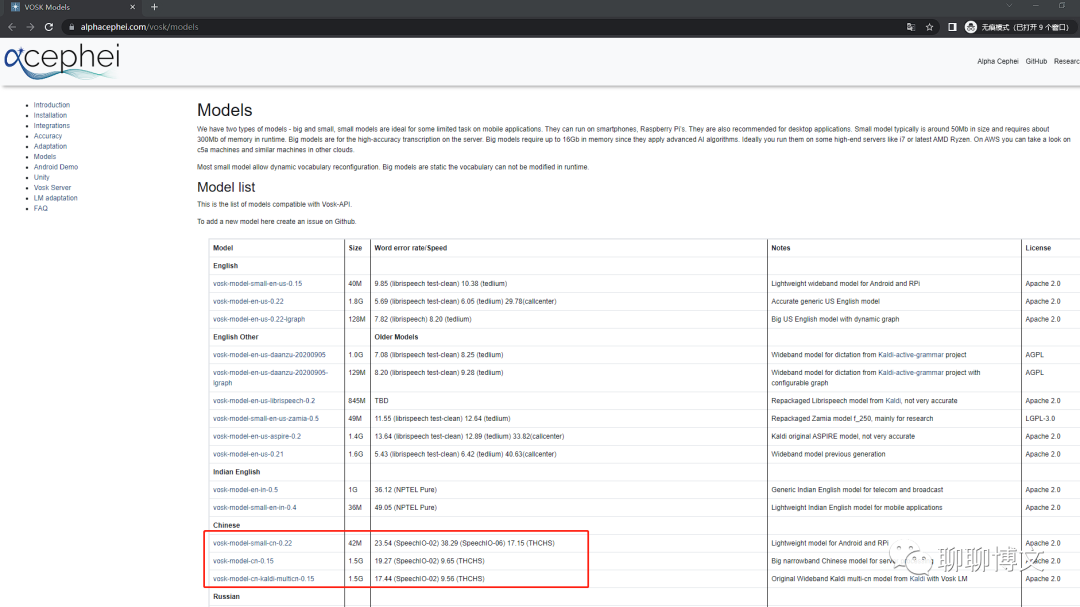
下载模型文件:
wget -c https://alphacephei.com/vosk/models/vosk-model-small-cn-0.22.zip wget -c https://alphacephei.com/vosk/models/vosk-model-cn-0.15.zip wget -c https://alphacephei.com/vosk/models/vosk-model-cn-kaldi-multicn-0.15.zip
如果下载过慢,可从如下链接获取:
https://pan.baidu.com/s/1NlmSejpFmUygcCgL4hvGGA
关注微信公众号(聊聊博文,文末可扫码)后回复 2022052101 获取提取码。
语音识别测试
1、修改测试代码
python示例代码路径:vosk-apipythonexample
编辑 test_simple.py 文件,注释掉如下代码:
rec.SetPartialWords(True)
要不会报如下错误:
AttributeError: 'KaldiRecognizer' object has no attribute 'SetPartialWords'
2、配置模型文件
解压 vosk-model-cn-0.15.zip 文件,并将解压后的文件夹名称修改为 model ,目录结构如下:
3、测试语音识别
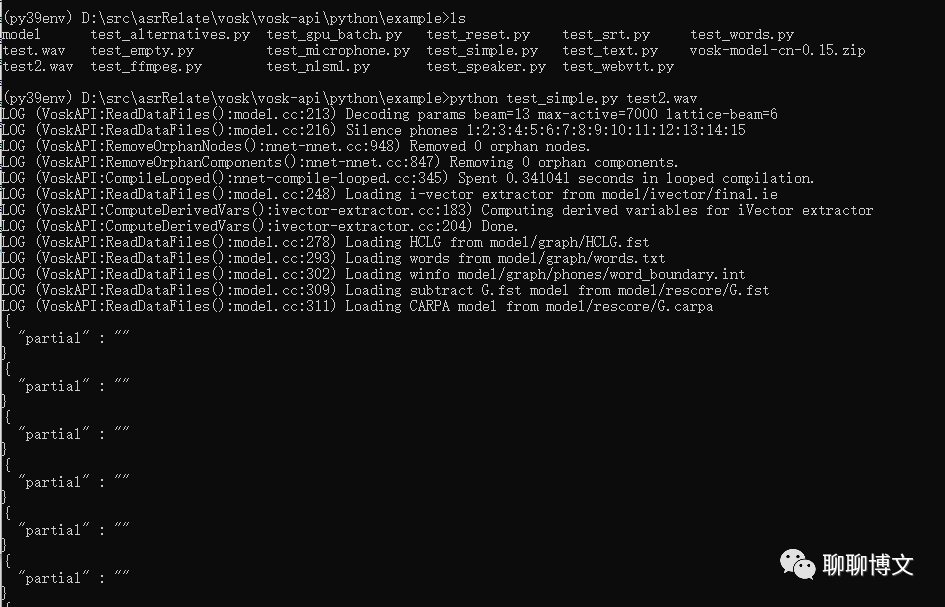
test2.wav内容:
自然语言理解和生成是一个多方面问题,我们对它可能也只是部分理解。
识别效果如下:

python使用vosk-server进行中文语音识别的演示视频,可从如下途径获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 202205210102 获取。
本文涉及源码及模型,可以从百度网盘获取:https://pan.baidu.com/s/1NlmSejpFmUygcCgL4hvGGA
关注微信公众号(聊聊博文,文末可扫码)后回复 2022052101 获取提取码。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:python使用vosk进行中文语音识别 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫