以下文章来源于微软研究院AI头条 ,作者微软亚洲研究院


专注科研22年,盛产黑科技

编者按:12月6日至12日,国际人工智能顶级会议 NeurIPS 2020(Conference and Workshop on Neural Information Processing Systems,神经信息处理系统大会)将在线上举办。相比前几年,2020年 NeurIPS 会议不管从论文投稿数量还是接收率都创下了记录:论文投稿数量创历史最高记录,比2019年增长了38%,但接收率却为史上最低。
目标检测(object detection)是计算机视觉中的基础任务,旨在定位图像或视频中某几类物体的坐标位置。本文将对微软亚洲研究院入选 NeurIPS 2020 中的目标检测工作进行介绍。
RelationNet++: Bridging Visual Representation for Object Detection via Transformer Decoder
论文链接:https://arxiv.org/abs/2010.15831
代码链接:https://github.com/microsoft/RelationNet2
现有的各种检测算法通常利用单一的格式来表示物体,比如 RetinaNet 和 Faster R-CNN 中的矩形框、FCOS 和 RepPoints 中的物体中心点、CornerNet 中的角点、以及 RepPoints 和 PSN 中的点集。
图1展示了四个主流框架的物体表示形式,以及初始化的物体表示形式如何形成最终的检测框。可以看到,不同的物体表示形式分别利用其框架的特征来回归最终的检测框。

图1:通用物体检测框架的物体表示形式
不同的物体表示形式都有其优缺点,例如矩形框表示的优点是更符合现有的物体标注;中心点表示可以避免负责的锚点(anchor)设计,对小物体也更友好;角点表示则对于定位更加准确,对大物体地检测更好、更准。
但由于这些不同表示在特征提取上的异构性和非均匀性,很难将它们有机地融合在一个检测框架中。因此,微软亚洲研究院的研究员们设计了一个 BVR (Briding Visual Representations) 模块来弥合不同的表达方法,它利用 Transformer 中的解码器来实现异构的各种物体表示之间的联系。
对于一个常见的检测器,其使用的物体表示形式被称之为“主表示”(master representation),而其它物体表示形式被称为“辅助表示“(auxiliary representation)。
在 BVR 模块中,主表示作为查询(query),类似于机器翻译中的目标语言,辅助表示作为关键字(key),可类比为机器翻译中的源语言,于是就可以将辅助表示的信息融合到主表示中,增强主表示的特征并最终帮助这一检测器。
BVR 模块可以很方便地插入到主流的检测器中,并广泛提升这些检测器的性能,例如在 Faster R-CNN、RetinaNet、FCOS 以及 ATSS 上,这一模块均带来了 1.5~3.0AP 的性能提升。图2展示了如何将 BVR 模块插入到 RetinaNet 中。
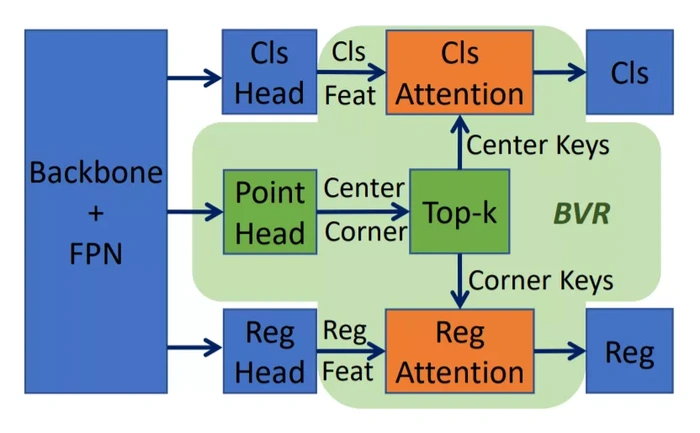
图2:如何将 BVR 模块插入到 RetinaNet 中
RetinaNet 中,在基于矩形框的锚点表示分支的基础上,额外增加了关于点的预测的头部网络分支,用于预测中心点(center)和角点(corner),并作为主分支的辅助表示(auxiliary representation)。在建模主表示和辅助表示间关系时,需同时考虑表观间的关系,如果将所有的中心点/角点都作为查询输入的话,将会带来极大的计算复杂度。
因此,研究员们提出了只利用得分 top-k 的查询选择策略来降低运算、提升效果,并且利用空间域插值的方式来计算几何关系,进一步降低运算代价。关于如何将 BVR 插入到 FCOS、Faster R-CNN 以及 FOCS 中,请阅读原论文进行了解。
最后,将 BVR 模块插入到 ATSS 中时,该模型被称之为 RelationNet++,在 COCO test-dev 集合上达到了 52.7 AP 的性能,如表1所示。
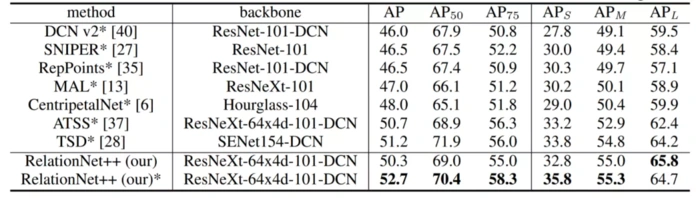
表1:RelationNet++ 在 COCO test-dev 集合上达到了 52.7 AP 的性能
需要注意的是,不久前的 DETR 检测器在视觉领域取得了较大的影响。DETR 主要探讨了 Transformers 应用于物体检测领域的可行性,而 BVR 则关注于提升物体检测器,通过弥合不同物体表示的优点,从而取得更高的性能。
另一方面,在建模上两种方式也有所不同,BVR 采用的是稀疏健值(key),并证明了其相比稠密健值更加有效且高效。
RepPoints v2: Verification Meets Regression for Object Detection
论文地址:https://arxiv.org/abs/2007.08508
代码地址:https://github.com/Scalsol/RepPointsV2
物体定位在物体检测任务中是非常重要的组成部分,传统的方法如 Faster-RCNN、RetinaNet 采用的是一种“粗验证,细回归”的范式,它们首先会铺设若干预设好大小的锚点,然后再通过计算锚点与真实框之间的偏移来调整锚点的位置与大小来完成物体定位。
最近,一些基于中心点的“纯回归”无锚点(anchor-free)方法,如 FCOS、RepPoints 等却取得了与“粗验证,细回归”方法可比,甚至更好的表现,这不禁让人对物体定位中验证步骤的必要性产生怀疑。
但与此同时,有一系列基于“纯验证”的方法也取得了不错的结果,代表方法就是 CornerNet。通过比较可以发现此类方法在产生高质量(AP90)框的能力上要远远高出上述两类方法。受此启发,微软亚洲研究院的研究员们发现通过在 RepPoints 这样一个纯回归的框架上引入合适的验证任务,能够给模型的表现带来很大提升。
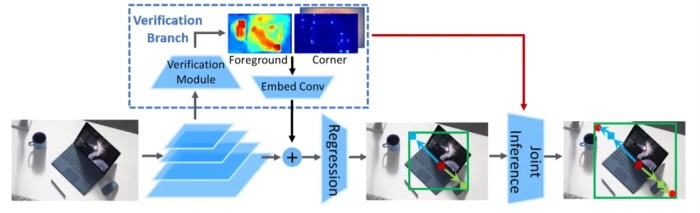
图3:融合方法介绍
如图3所示,研究员们将验证任务作为 RepPoints 的一个旁支,让其高效地与主网络进行特征与结果层面的交互,同时不影响 RepPoints 本身基于点表示的特性。
本篇论文主要引入了两种验证任务:一是角点验证,判断特征图上的像素点是否是某个真实框的左上(右下)角点;二是框内前景验证,将物体的外接框作为该物体的粗糙掩码,然后将其当做一个语义分割任务来进行学习。
通过引入这两个验证任务和加入与之相适应的修改,可以获得以下几点好处:
首先是更好的特征:验证任务可以提供训练时额外的监督信号并且验证分支的特征可以与回归分支的特征相融合,这种多任务学习的方式和特征融合的方式在 Mask R-CNN 等方法中已经被证明对提升模型表现非常有效。
其次是联合推断:在特征层面的融合之外,验证分支中的角点验证模块可以对回归分支的结果进行进一步的修正,获得更为精确的结果。
最后,由于本篇论文中提出的方法并不受到具体检测框架的限制,因此可以轻易地拓展到其他物体检测器上,同时也适用于其他视觉任务如实例分割。
表2展示了在不同的主干(backbone)网络下,该方法相比于 RepPoints v1 均能够获得2%左右的稳定提升。表3则比较了本文提出的检测器与其他检测器之间的性能。

表2:稳定的性能提升
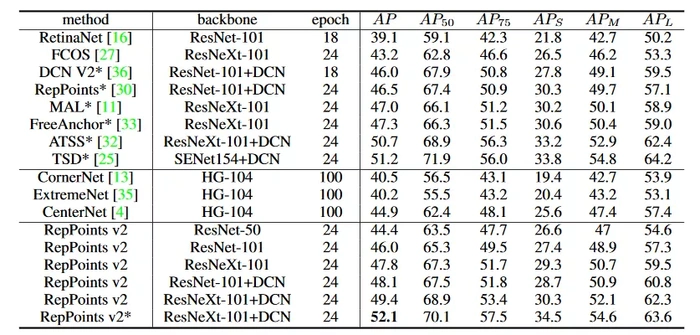
表3:与其他检测器性能比较
下面两个表格展示了在其它基检测器以及实例分割任务上本文方法的适用性。

表4:在 mmdetection 集合上,验证模块用于 FCOS 方法的实验结果

表5:在 COCO test-dev 集合上,验证模块用于 Dense RepPoints 方法的实验结果
图4展示了 RepPoints V1 和 V2 的预测结果,其中第一行为 V1 的预测结果,第二行为 V2 的预测结果。可以看到 V2 的结果更加准确。

图4:RepPoints V1 和 V2 的预测结果比较
Restoring Negative Information in Few-Shot Object Detection
论文链接:https://arxiv.org/abs/2010.11714
代码链接:https://github.com/yang-yk/NP-RepMet
受制于自身数量和样本获取等原因,不同类别的样本数量分布自然地呈现出长尾现象,类别间样本数量差异很大。深度学习模型往往在样本丰富的类别上能够取得较好的效果,而在样本稀缺的类别上表现却不尽如人意。但在自然界中,人类通常可以通过很少数量的样本就能够完成各项分类识别任务。
由此,小样本学习应运而生,其目标是利用样本丰富类别(base classes)提取先验知识并将其推广到弱监督小样本类别(novel classes)的新任务 [1]。
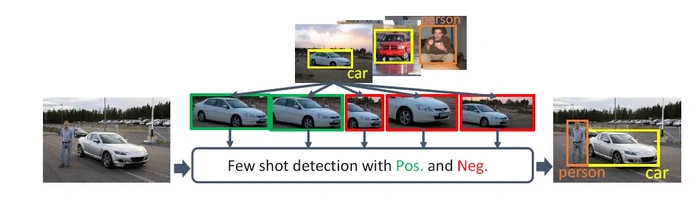
图5:目标检测示例
由于小样本类别上的样本极其有限,所以如何充分利用有限的样本信息就成为了小样本目标检测性能提升的关键。
现有的小样本目标检测工作(Meta R-CNN [2]、RepMet [3]等)是在样本丰富类别上训练主干网络或嵌入表示网络,然后通过小样本类别上的支持集(support set)提取和学习小样本集特征并进行小样本目标检测。然而这只利用了正样本(positive)的特征,却忽略了负样本(negative)尤其是困难负样本(hard negative)信息在小样本目标检测中的作用。
如图6所示,微软亚洲研究院的研究员们将与样本标签 IoU>0.7 的候选框定义为正样本信息,将 0.2<IoU<0.3 的候选框定义为负样本信息,基于 Faster R-CNN,在 RepMet 的基础上,新建了一个 NP-RepMet 的框架,综合利用正负样本信息可以更好地进行小样本检测。

图6:样本丰富类别训练过程
在样本丰富类别训练的过程中,RPN 和 DML Embedding Module 后通过两个全连接层分别对每个候选框提取正样本和负样本特征,并根据 IoU 对候选框进行正负样本分类。
研究员们通过联合训练的方式,利用正样本候选框的特征训练其正样本表示(图6黄色虚线框),利用负样本候选框的特征训练其负样本表示(图6黄色虚线框)。
然后,计算每个候选框的正样本特征与学习到的每个类别正样本表示的最小距离,计算每个候选框的负样本特征与学习到的每个类别负样本表示的最小距离。
最后,综合利用这两个距离,并将距离通过概率度量模块转换为分类概率进行每个候选框的分类。
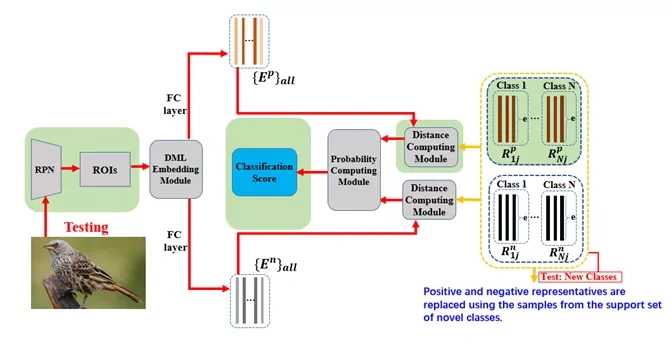
图7:小样本类别测试过程
小样本类别的测试过程如图7所示。首先利用有标签支持集上的样本,通过 DML Embedding Module 后全连接层提取到的特征,根据 IoU 进行小样本类别正样本表示和负样本表示的替换。对于查询集(query set)上的测试数据,其计算过程如上图红色箭头所示,与训练过程相同。
与 RepMet 和 Meta R-CNN 保持一致,研究员们分别在 ImageNet-LOC 和 Pascal VOC 上进行了实验,实验结果如下:
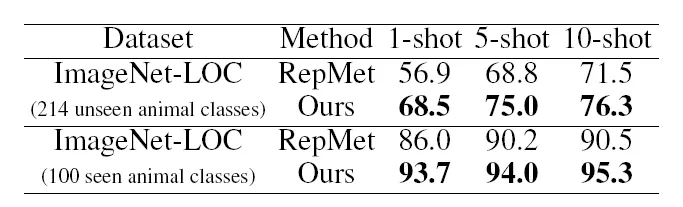
表6:在 ImageNet-LOC 上的实验结果
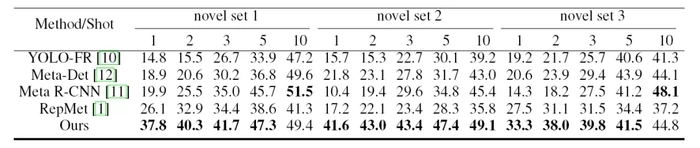
表7:在 Pascal VOC 上的实验结果
可以看到,通过综合利用正负样本信息,小样本目标检测能够取得较大性能提升。相比于 RepMet 和 Meta R-CNN,NP-RepMet 在 5-way 1-shot 条件下,于 ImageNet-LOC 和 Pascal VOC 数据集上的 mAP 均取得了10%以上的提升。
参考文献:
[1] Wang Y, Yao Q, Kwok J T, et al. Generalizing from a few examples: A survey on few-shot learning[J]. ACM Computing Surveys (CSUR), 2020, 53(3): 1-34.[2] Yan X, Chen Z, Xu A, et al. Meta R-CNN: Towards general solver for instance-level low-shot learning, CVPR 2019.[3] Karlinsky L, Shtok J, et al. RepMet: Representative-based metric learning for classification and few-shot object detection, CVPR 2019.
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:NeurIPS 2020 | 微软亚洲研究院论文摘录之目标检测篇 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 