尽管人工智能在我们一部分人中引起了恐惧,但它也以多种方式让我们受益。医疗保健中的人工智能正在通过提供协助来彻底改变医疗行业。本篇博客将帮助您了解人工智能在医疗保健领域的积极影响。
以下是本文中将要涵盖的主题:
- 什么是人工智能?
- 医疗保健中的人工智能
- 什么是机器学习?
- 什么是深度学习?
- 动手实践
什么是人工智能?
人工智能是使用机器学习、深度学习、自然语言处理和许多其他技术来构建可以执行高级计算和解决复杂问题的人工智能模型的过程。
现在让我们了解人工智能在医疗保健领域是如何应用的。
医疗保健中的人工智能
自 1950 年代引入人工智能以来,它一直在影响各个领域,包括市场营销、金融、游戏行业,甚至音乐艺术。然而,人工智能的最大影响是在医疗保健领域。PWC(Pricewaterhouse Coopers)最新报告显示,到2030年,人工智能将为世界经济额外贡献15.7万亿美元,其中影响最大的将是医疗保健领域。
在下面的部分中,您将了解如何使用 AI 来解决现实世界的问题。
数据管理中的人工智能
人工智能通过实施认知技术来解开大量医疗记录并执行强大的诊断,从而使医疗保健组织受益。以使用人工智能和机器学习来预测用户意图的预测服务提供商 Nuance 为例。

在组织的工作流程中实施 Nuance,可以开发个性化的用户体验,使公司能够采取更好的服务来增强客户体验和整体的业务收益。
以下是 Nuance 的主要功能:
-
提高服务效率:通过学习能够精准预测出用户的意图 ,并提出最准确的解决办法,确保满足消费者的实际需求。
-
减少客户呼叫、咨询时间:预测客户的意图,并将客户转移到其他在线服务上,极大地减少了呼叫量和咨询时间,降低了大量成本。
-
减少客户流失:使用机器学习和自然语言处理技术,根据客户的历史数据、搜索记录、当前的情绪等各种因素,预测可能降低企业服务好评率的客户行为,并采取适当的行动来避免此类客户流失。

- 自动化处理繁琐的任务:通过一个自动化系统处理重复单调任务,该系统还可以发送短信通知。使用此类基于 AI 的聊天机器人可以使服务变得更加简单。
医学诊断中的人工智能
“到 2024 年,由 AI 驱动的医学成像和诊断应该会增长 40% 以上,超过 25 亿美元。” –全球市场洞察力。
借助神经网络和深度学习模型,人工智能正在彻底改变医学图像诊断领域。它接管了 MRI 扫描的复杂分析,并使其成为一个更简单的过程。
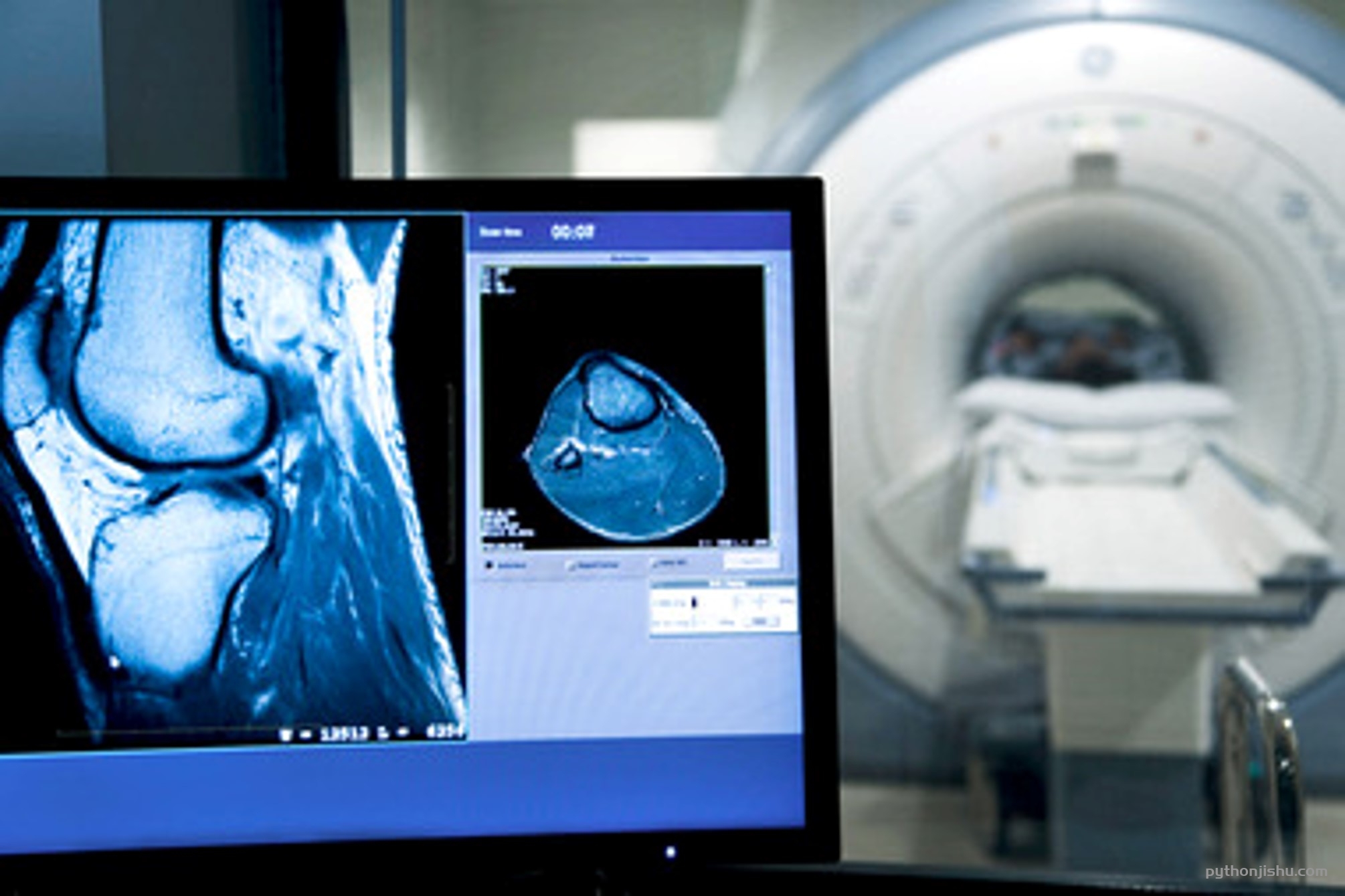
- 由于 MRI 扫描包含的信息量大,因此很难对其进行分析。正常的 MRI 分析需要几个小时,研究人员试图从大型数据集中得出结果,等待数小时以等待计算机生成扫描结果。
- 可以在神经网络的帮助下分析大型和复杂的数据集,这正是麻省理工学院的一个研究团队所实现的。他们开发了一个名为 VoxelMorph 的神经网络,该网络接受了大约 7000 次 MRI 扫描数据集的训练。
- 神经网络的功能是在一端输入数据,该数据在整个网络中进行转换,直到形成最终所需的输出。神经网络的工作原理是权重和偏差。
VoxelMorph 成功击败了传统的 MRI 分析方法。神经网络只需几秒钟即可执行 MRI 分析,而传统 MRI 程序需要数小时才能完成分析。
早期检测中的人工智能
人工智能在心脏病发作等疾病的早期预测中发挥了关键作用。许多基于 AI 的可穿戴健康追踪器已被开发出来,用于监测人的健康状况,并在设备收集到异常或不太可能的情况时显示警告。此类可穿戴设备的示例包括 Fitbit、Apple Watch 等。

“预防胜于治疗”,这是最新发布的 Apple Watch 背后的座右铭。
-
苹果公司使用人工智能制造了一款可以监测个人健康的手表。
-
这款手表收集人的心率、睡眠周期、呼吸频率、活动水平、血压等数据,并全天候 24/7 记录这些测量值。
-
然后使用机器学习和深度学习算法对收集到的数据进行处理和分析,以构建预测心脏病发作风险的模型。
多亏了 Apple Watch,一个名叫Scott Killian 的人救了他的命。
医疗救助中的人工智能
随着医疗救助需求的增长,基于人工智能的虚拟护士的发展也在增加。根据最近的一项调查,到 2027 年,虚拟护理助理的最大近期价值将达到 200 亿美元。
Sensely 是虚拟护士的一个例子,它实施自然语言处理、语音识别、机器学习和与血压袖带等医疗设备的无线集成,为患者提供医疗帮助。
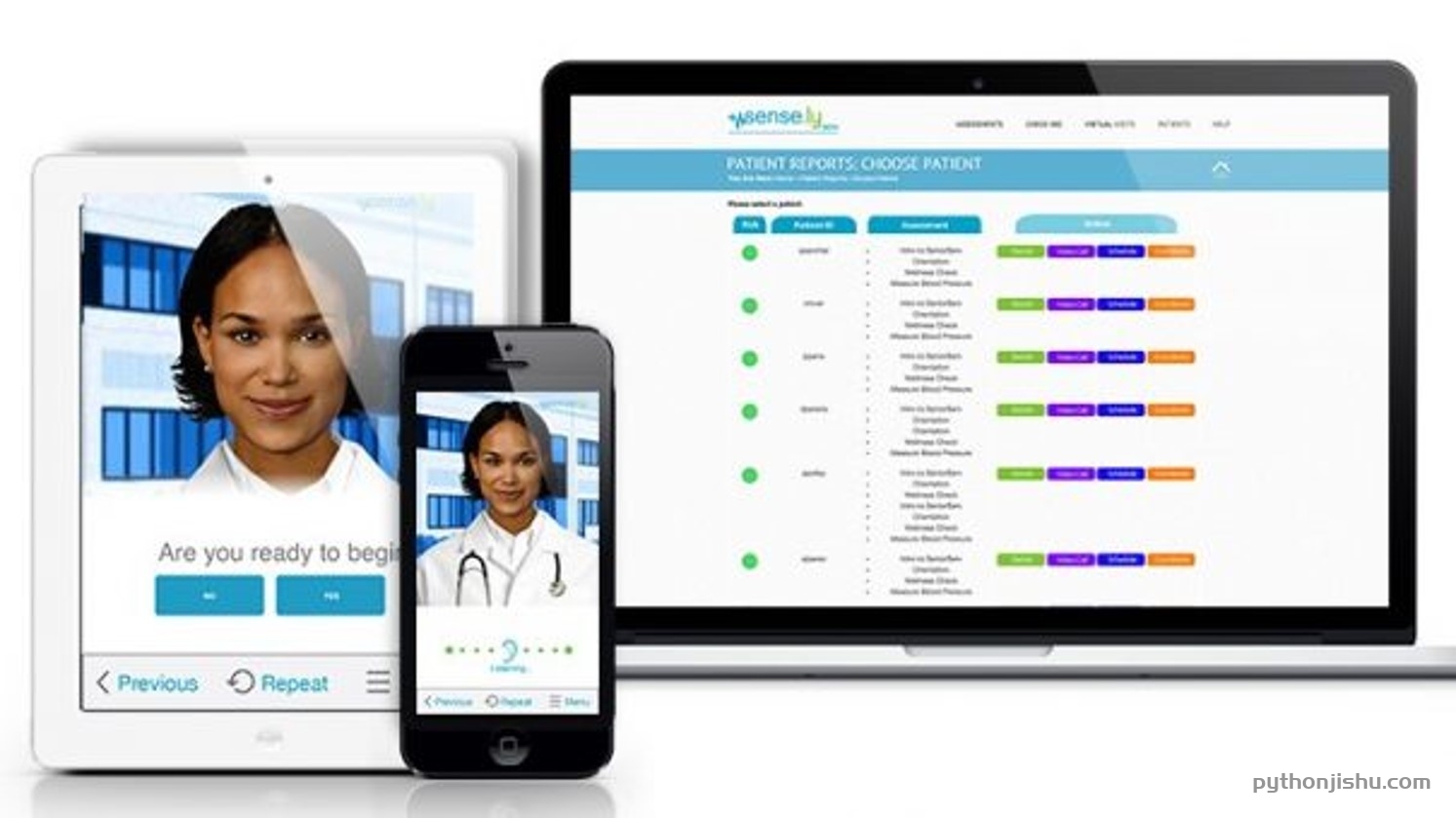
以下是虚拟护士 Sensely 提供的主要功能列表:
- 自我护理
- 临床建议
- 安排约会
- 护士专线
- 急诊方向
随着医疗保健领域的此类革命,很明显,尽管存在风险和所谓的“威胁”,人工智能仍在许多方面使我们受益。
决策中的人工智能
人工智能在决策制定中发挥了重要作用。不仅在医疗保健行业,人工智能还通过研究客户需求和评估任何潜在风险来改善业务。
人工智能在决策中的一个强大用例是使用手术机器人,它可以最大限度地减少错误和变化,并最终帮助提高外科医生的效率。达芬奇就是这样一种手术机器人,它的名字非常贴切,它允许专业外科医生以比传统方法更好的灵活性和控制力来实施复杂的手术。

达芬奇的主要特点包括:
- 用一套先进的仪器帮助外科医生
- 在控制台实时翻译外科医生的手部动作
- 生成清晰、放大的手术区域 3D 高清图像
手术机器人不仅协助决策过程,而且还通过提高准确性和效率来提高整体性能。
所以他们是一对人工智能在医疗保健领域的实际应用。在整个博客中,我提到了人工智能的两个非常重要的领域,机器学习和深度学习。让我们了解这些术语的确切含义。
什么是机器学习?
机器学习是向机器提供大量数据的过程,以便它们可以解释、处理和分析这些数据,从而产生有利于组织的可操作见解。
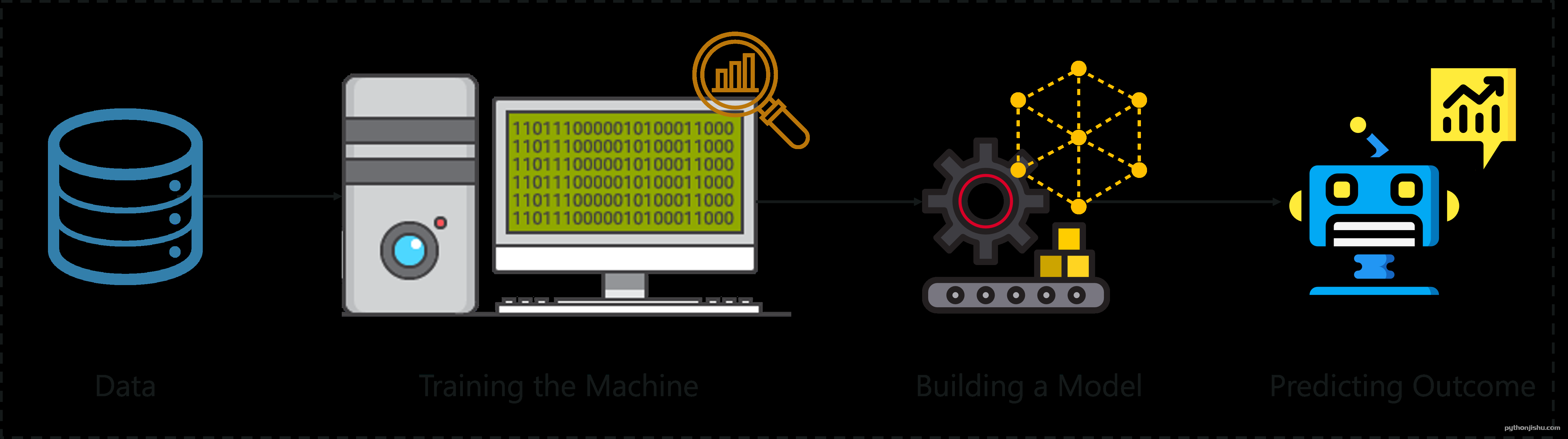
机器学习的一个更高级的概念是深度学习。让我们了解什么是深度学习。
什么是深度学习?
深度学习是机器学习的一个更高级的领域,它使用神经网络的概念来解决需要高维数据和自动特征提取的更复杂的问题。
现在让我们看看如何使用医疗保健中的人工智能案例可以通过使用深度学习概念来实施。
使用 Python 进行深度学习
接下来我将使用 Python 来运行这个实例演示。
问题陈述:研究威斯康星州乳腺癌(诊断)数据集,并为预测乳腺癌分期为 M(恶性)或 B(良性)的神经网络分类器建模。
数据集描述:数据集包含样本中存在的细胞核的描述性信息。它包含大约 32 个属性/特征,有助于对特定样本是否癌变进行分类。您可以在此处找到数据集。
逻辑:构建一个二元神经网络,可以将细胞样本正确分类为癌性或非癌性。产生的输出将是一个包含两个值的分类变量:
- 恶性——癌细胞
- 良性——非癌细胞
既然您知道了问题陈述背后的逻辑,是时候戴上侦探眼镜开始编码了。
第一步:导入需要的包
# Linear algebra
import numpy as np
# Data processing
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt2
from sklearn import preprocessing
from subprocess import check_output第二步:读取输入数据
# Import the data set
data = pd.read_csv('C://Users//NeelTemp//Desktop//data.csv')
#Display the first few observations in the data set
print(data.head())
id diagnosis ... fractal_dimension_worst Unnamed: 32
0 842302 M ... 0.11890 NaN
1 842517 M ... 0.08902 NaN
2 84300903 M ... 0.08758 NaN
3 84348301 M ... 0.17300 NaN
4 84358402 M ... 0.07678 NaN
[5 rows x 33 columns]第三步:数据处理
# Cleaning and modifying the data
data = data.drop('id',axis=1)
data = data.drop('Unnamed: 32',axis=1)
# Mapping Benign to 0 and Malignant to 1
data['diagnosis'] = data['diagnosis'].map({'M':1,'B':0})
# Scaling the dataset
datas = pd.DataFrame(preprocessing.scale(data.iloc[:,1:32]))
datas.columns = list(data.iloc[:,1:32].columns)
datas['diagnosis'] = data['diagnosis']
# Creating the high dimensional feature space X
data_drop = datas.drop('diagnosis',axis=1)
X = data_drop.values第 4 步:构建神经网络
# Create a feed forward neural network with 3 hidden layers
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Input
from keras.optimizers import SGD
model = Sequential()
model.add(Dense(128,activation="relu",input_dim = np.shape(X)[1]))
model.add(Dropout(0.25))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])第五步:数据拼接和交叉验证
# Fit and test the model by randomly splitting it
# 67% of the data for training and 33% of the data for validation
model.fit(X, datas['diagnosis'], batch_size=5, epochs=10,validation_split=0.33)
# Cross validation analysis
from sklearn.model_selection import StratifiedKFold
# K fold cross validation (k=2)
k = 2
kfold = StratifiedKFold(n_splits=2, shuffle=True, random_state=seed)
cvscores = []
Y = datas['diagnosis']
for train, test in kfold.split(X, Y):第 6 步:运行模型
# Fit the model
model.fit(X[train], Y[train], epochs=10, batch_size=10, verbose=0)
Train on 381 samples, validate on 188 samples
Epoch 1/10
5/381 [..............................] - ETA: 2:39 - loss: 0.5185 - acc: 0.8000
45/381 [==>...........................] - ETA: 16s - loss: 0.6274 - acc: 0.6444
100/381 [======>.......................] - ETA: 6s - loss: 0.5755 - acc: 0.7100
155/381 [===========>..................] - ETA: 3s - loss: 0.4560 - acc: 0.7871
215/381 [===============>..............] - ETA: 1s - loss: 0.3723 - acc: 0.8326
260/381 [===================>..........] - ETA: 1s - loss: 0.3404 - acc: 0.8538
305/381 [=======================>......] - ETA: 0s - loss: 0.3252 - acc: 0.8623
381/381 [==============================] - 3s 7ms/step - loss: 0.2802 - acc: 0.8845 - val_loss: 0.0870 - val_acc: 0.9628
Epoch 2/10
5/381 [..............................] - ETA: 0s - loss: 0.0647 - acc: 1.0000
165/381 [===========>..................] - ETA: 0s - loss: 0.0966 - acc: 0.9758
381/381 [==============================] - 0s 314us/step - loss: 0.0944 - acc: 0.9659 - val_loss: 0.0497 - val_acc: 0.9894
第 7 步:模型评估
# evaluate the model
scores = model.evaluate(X[test], Y[test], verbose=0)
# Print scores from each cross validation run
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
acc: 97.89%
acc: 97.89%
cvscores.append(scores[1] * 100)
print("%d-fold cross validation accuracy - %.2f%% (+/- %.2f%%)" % (k,np.mean(cvscores), np.std(cvscores)))
2-fold cross validation accuracy - 97.89% (+/- 0.00%)因此,正如您所见,神经网络为我们提供了 97.89% 的准确率,这是一个相当不错的分数。如果您希望进一步改进模型,可以执行参数调整和优化技术,例如具有更有效值的 drop-off 方法。
如果您仍然对人工智能感到好奇,这里有一些您可能感兴趣的博客:
以上就是人工智能在医疗保健中的应用方法。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:人工智能在医疗领域的应用实战(附源码)! - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
