自从2020年进入公司从学生变成社会人以来,接手的第一项工作就是检查并整改公司终端的季度考核指标;
季度考核是公司总部要求的,每季度一次(废话。。),需要管理的终端量在1500台左右;
主要就是检查内网终端各类管理软件(桌面管理、防病毒等等)的安装率与版本合规情况;
各类软件都有总部提供的平台,需要做的就是去各个平台导出数据、Excel汇总计算,
然后看看哪项考核不达标,通知负责终端维护的外包公司去各个地点做维护;
这项工作虽然不难,但是每季度末都要重复地检查确保达标,因此工作量很大,每天至少要花一两个小时;
其实在刚接手的时候就有做一个自动检查系统的想法,奈何当时的我技术力还不够;
并且刚刚进入公司需要学习的东西太多,就暂且搁置了;
22年一季度不是很忙,就利用工作之余的上班时间做出来了;
每天自动出结果发给外包公司,很大程度上减少了季度考核时的工作量;
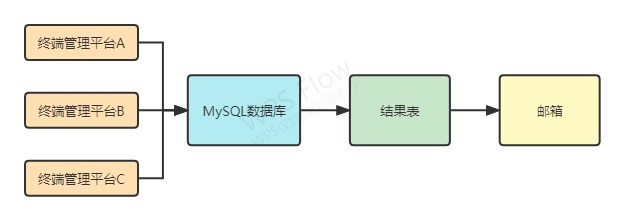
主要的实现过程大致是三个步骤:
一、利用Python的selenium WEB自动化工具去各个平台下载数据;
二、利用Python的pymysql数据库工具将数据文件导入MySQL数据库;
三、MySQL数据库按照考核标准计算结果,生成结果文件,再通过邮件发送结果文件。
结构图:

一、利用Python的selenium WEB自动化工具去各个平台下载数据
其实用浏览器控制去导数可靠性比较差,并且效率比较低,但是去找各个平台的项目组对接数据库实在太麻烦了,人家也不见得乐意开放数据库给你用;
并且这个工具最多季度末的时候一天跑两三次,并不需要太高的效率,所以就采用了selenium WEB自动化;
selenium的学习参考的是腾讯云社区的教程:Python中Selenium库使用教程详解 - 云+社区 - 腾讯云 (tencent.com);
首先是pip安装selenium,指定国内源加快下载速度:
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple我用的是谷歌浏览器版本99,需要下载一个对应版本99的驱动程序才能调起浏览器,下载地址:http://chromedriver.storage.googleapis.com/index.html;
使用示例:
from selenium import webdriver
from time import sleep
# 实例化一款浏览器
browser = webdriver.Chrome(executable_path = "chromedriver.exe")
# 对指定的url发起请求
browser.get("https://www.bilibili.com/")
# 设定窗口大小
browser.set_window_size(1600, 900)
# 在页面中寻找元素
element = browser.find_element_by_xpath('/html/body/div[2]/div[1]/div[1]/ul[2]/li[1]/li/div/div/span') # “登录”
# 对元素进行操作
element.click() # 点击
# 延时3秒,等待页面回应
sleep(3)
# 关闭浏览器
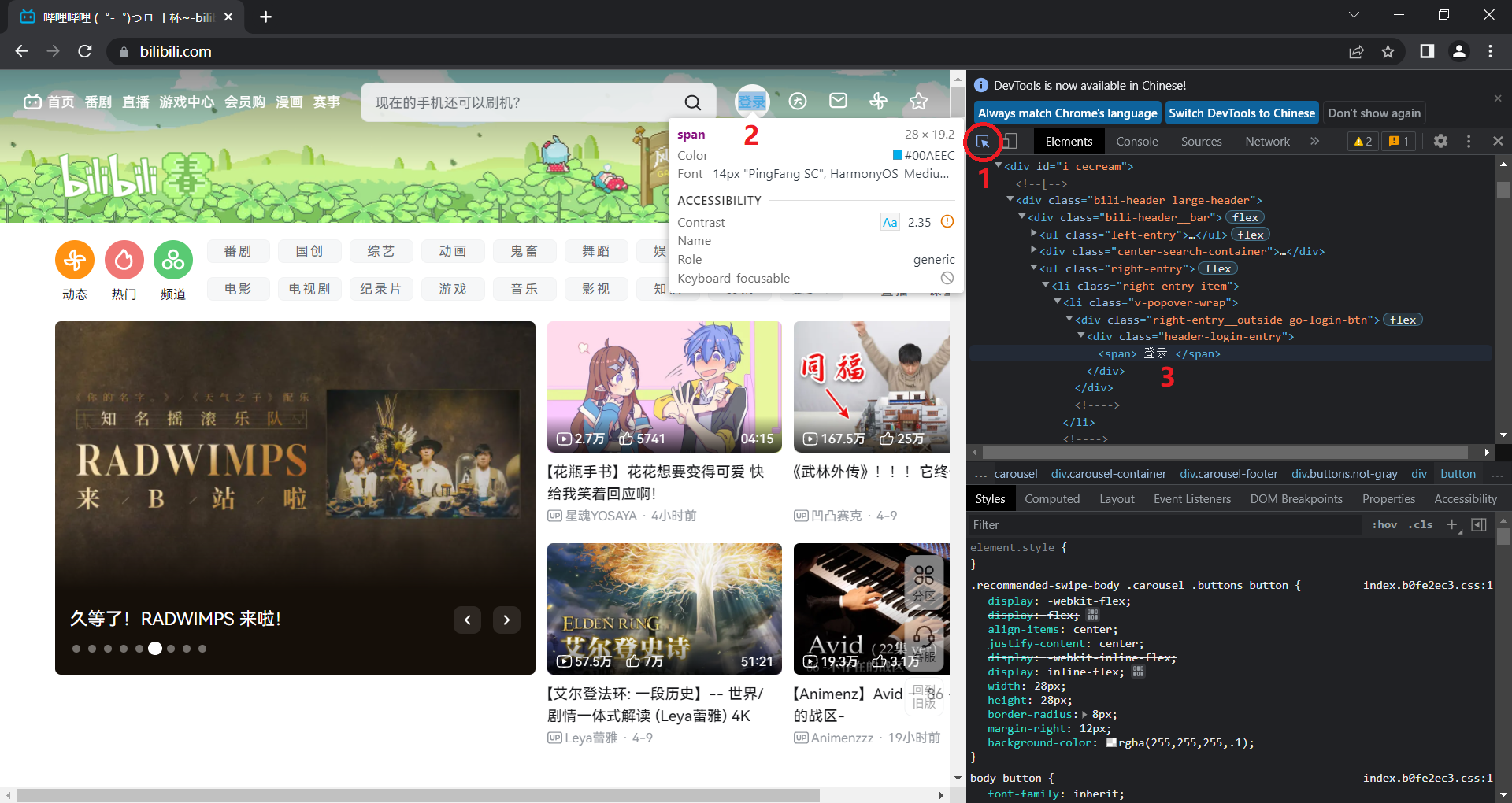
browser.quit()一般浏览器都可以用F12进入开发工具查看页面中的元素,点击1处的工具,再点击2处页面中任意的元素,在3处会跳转并高亮元素在HTML代码中的位置;
我是按照完整xpath来寻找元素的browser.find_element_by_xpath(),也可以使用元素的id、name、标签等等;
点击元素后element.click(),如果有后续操作可以添加一个延时,否则页面可能来不及响应。
1. 切换frame
某些页面会用到frame的结构,比如:
<html lang="en">
<head>
<title>FrameTest</title>
</head>
<body>
<iframe src="a.html" id="frame1" name="myframe"></iframe>
</body>
</html>在frame中的元素无法被browser.find_element_by_xpath()直接寻找到,需要进行frame的切换:
frame = browser.find_elements_by_tag_name('iframe')[1] # 定义frame
browser.switch_to.frame(frame) # 切换frame
element = browser.find_element_by_xpath('XXXXXX') # 寻找frame中的元素
element.click() # 点击元素
browser.switch_to.default_content() # 退出frame回到主体结构如果需要回到主体结构继续操作要使用browser.switch_to.default_content()。
2. 切换浏览器窗口
某些地方点击后会新建标签页或者弹出新的浏览器窗口,此时就需要切换窗口去继续操作:
windows = browser.window_handles
browser.switch_to.window(windows[1]) # 打开了新页面,需要切换窗口
element = browser.find_element_by_xpath('XXXXXX')
element.click()3. 新建标签页
如果不想关闭浏览器,需要打开新的标签页继续操作:
js = "window.open('https://www.douban.com/')"
browser.execute_script(js) # 在新标签页中访问4. 识别简单的验证码
本来我以为用selenium查找元素一个一个去点是很重复无聊且枯燥的工作;
直到我遇到了一个平台登录的时候需要输入一个图片验证码(其他平台都是只需要账号密码),事情突然变得有趣了起来;
大概的思路是先截取验证码的图片,然后用图片识别文字的工具来识别验证码,再输入到网页验证码框里;
首先要解决把验证码图片截出来的问题,我参考的是selenium验证码识别之局部截图 - 简书 (jianshu.com);
然后选择了一个比较轻量的(因为要放到内网,太大了不好处理)图片识别文字的工具——pytesseract;
pytesseract的安装和使用参考的是Python OCR工具pytesseract详解_测试开发小记的博客-CSDN博客_pytesseract;
因为图片识别验证码是一个不一定成功且准确的事件,所以我在这边使用了try finally结构,重复识别验证码并输入;
我在使用过程中识别正确率很低,一般要重复识别十几次几十次才能通过;
这个工具的使用场景并不需要追求很高的效率,因此只要能通过一次就能满足我的需求;
下面是这部分功能的代码:
from selenium import webdriver
from time import sleep
from PIL import Image
import pytesseract
# 重复尝试识别验证码,失败后刷新重试,成功后寻找不到try部分中第一个元素,跳转到finally部分
try:
r = 0
while True:
# 输入用户名密码,识别验证码,点击“登录”
element = browser.find_element_by_xpath('XXXXXX') # 用户名
element.send_keys('用户名')
element = browser.find_element_by_xpath('XXXXXX') # 密码
element.send_keys('密码')
# 截图识别验证码并输入
browser.save_screenshot('browser.png') # 对网页进行截图
code_png_lel = browser.find_element_by_xpath('XXXXXX') # 验证码
location = code_png_lel.location # 获取验证码元素所在位置
print('location', location)
size = code_png_lel.size # 获取验证码元素大小
print('size', size)
rangle = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height'])) # 找到验证码在网页截图中的位置
print('rangle', rangle)
i = Image.open('browser.png')
frame = i.crop(rangle) # 按照验证码位置截图
frame.save('code.png')
j = Image.open('code.png')
string = pytesseract.image_to_string(j) # 识别验证码图片中的文字
string = string.replace(' ', '') # 删除识别结果中的空格
print(string)
element = browser.find_element_by_xpath('XXXXXX') # 验证码输入框
element.send_keys(string) # 输入删除空格后的识别结果
element = browser.find_element_by_xpath('XXXXXX') # “登录”
element.click() # 点击登录
browser.refresh() # 刷新页面
r = r + 1
print(r)
# 成功后跳出循环,继续操作
finally:
sleep(5)
element = browser.find_element_by_xpath('XXXXXX')
element.click()二、利用Python的pymysql数据库工具将数据文件导入MySQL数据库
获取各个平台的多张数据表后,下一步就是将数据导入MySQL数据库中进行计算(其实是两步,“导入”和“计算”);
首先,各个平台导出数据表的格式各不相同,有xlsx,有xls,有csv;
需要把它们全部整合成统一的格式csv,编码转为utf-8;
有些表存在很多无效行,全部导入数据库会浪费很多时间,需要进行预处理;
xlsx或xls转csv:
import pandas
def xlsx_to_csv(xlsx_file_path, csv_file_path):
print('>>文件%s格式转换处理中。。。' % xlsx_file_path)
file_xlsx = pandas.read_excel(xlsx_file_path, index_col=0)
file_xlsx.to_csv(csv_file_path, encoding='utf-8')
print('>>文件%s格式已转换为csv' % xlsx_file_path)xlsx或xls转csv,并删除无效表头(header = None):
import pandas
def xlsx_to_csv_noheader(xlsx_file_path, csv_file_path):
print('>>文件%s格式转换处理中。。。' % xlsx_file_path)
file_xlsx = pandas.read_excel(xlsx_file_path, index_col=0)
file_xlsx.to_csv(csv_file_path, encoding='utf-8', header = None)
print('>>文件%s格式已转换为csv,并删除了无效表头' % xlsx_file_path)xlsx或xls转csv,并按照某关键字筛选(apply(lambda a:a == '关键字')):
import pandas
def xlsx_to_csv_bgfxm(xlsx_file_path, csv_file_path):
print('>>文件%s格式转换处理中。。。' % xlsx_file_path)
file_xlsx = pandas.read_excel(xlsx_file_path, index_col=0)
file_xlsx = file_xlsx.loc[file_xlsx['列名'].apply(lambda a:a == '关键字')]
file_xlsx.to_csv(csv_file_path, encoding='utf-8', index = False)
print('>>文件%s格式已转换为csv' % xlsx_file_path)csv中按行删除某列中的重复值,保留重复值中从上到下的第一条(keep = 'first'):
import pandas
def delete_duplicates(csv_file_path, keyword):
print('>>文件%s删除%s重复记录处理中。。。' % (csv_file_path, keyword))
csv_file = pandas.read_csv(csv_file_path)
csv_file = csv_file.drop_duplicates(subset = [keyword], keep = 'first', inplace = False)
csv_file.to_csv(csv_file_path, encoding='utf-8', index = False)
print('>>文件%s删除%s重复记录已完成' % (csv_file_path, keyword))import codecs
def ansi2uft8(file):
print('>>文件%s编码转换处理中。。。' % file)
f = codecs.open(file, 'r', 'ansi')
ff = f.read()
file_name = file.split('\')[-1]
file_path = file.replace(file_name, "")
file_object = codecs.open(file_path + '\' + file_name, 'w', 'utf-8')
file_object.write(ff)
print('>>文件%s编码已转换为UTF-8' % file)某些平台导出的csv文件每行末尾都会有一个英文逗号“,”,会导致导入数据库的时候表头出现空字段、每行多一个空值,因此需要删掉:
import os
def droplastcomma(file):
print(">>文件%s末尾','删除处理中。。。" % file)
reader = open(file, 'r', encoding = 'utf8')
write_file = file.strip()[:-4] + '_temp.csv'
writer = open(write_file, 'w', encoding = 'utf8')
rows_raw = reader.readlines()
for row in rows_raw:
row = row.rstrip()[:-1] + 'n'
writer.writelines(row)
reader.close()
writer.close()
os.remove(file)
os.rename(write_file, file)
print(">>文件%s每行末尾','已删除" % file)接下来就是重头戏,连接数据库并导入csv文件;
首先需要安装一个MySQL数据库,安装完后建立一个空的数据库;
Python调用MySQL的组件为pymysql,以下为实现过程:
import pymysql
# 连接数据库
db = pymysql.connect(
host = '127.0.0.1',
port = 3306,
user = '用户名',
passwd = '密码',
db = '库名',
charset = 'utf8')
# 建立连接游标
cursor=db.cursor()
print('>>已连接数据库,处理中。。。')
# 函数:删除旧表,从csv文件创建新表
def load_csv(csv_file_path, table_name, database, decoding):
print(">>文件%s开始创建表。。。" % csv_file_path)
# 打开文件,创建表和表头
file = open(csv_file_path, 'r', encoding = decoding)
# reader:readline读取csv文件第一行,用于创建表头
reader = file.readline()
b = reader.split(',')
colum = ''
head = ''
# for循环:从csv文件第一行逐个编辑字符串,创建表头字符串
for a in b:
# 去掉每个字符串的"、换行
c = a.strip('"' and '"n')
# head:用于逐行插入数据时选择表头,中文表头需要加间隔号(1左边的键)
head = head + "`" + c + "`" + ','
# colum:用于创建表时指定表头,中文表头需要加间隔号(1左边的键),创建表时需要加数据类型(varchar(255))
colum = colum + "`" + c + "`" + ' varchar(255),'
# [:-1]去除末尾逗号
colum = colum[:-1]
head = head[:-1]
cursor.execute('use %s' % database)
cursor.execute('set names utf8')
cursor.execute('set character_set_connection=utf8')
cursor.execute('drop table if exists %s' % table_name)
# 创建表,增加id列
create_sql = 'create table if not exists ' + table_name + ' (id INT,' + colum + ')' + ' DEFAULT CHARSET=utf8'
cursor.execute(create_sql)
# while循环:逐行导入csv
# rows_raw:readlines逐行读取csv
rows_raw = file.readlines()
count_rows = len(rows_raw)
i = 0
while i < count_rows:
ii = str(i + 1)
d = rows_raw[i]
d = d.split(',')
rows = ''
for e in d:
# 去掉每个字符串的"、换行、(会在insert时报错)
f = e.strip('"')
f = f.strip('"n')
f = f.strip('\')
rows = rows + "'" + f + "'" + ','
# rows增加id列数值
rows = "'" + ii + "'," + rows[:-1]
print(rows)
insert_sql = 'insert into %s (`id`,%s) values (%s)' % (table_name, head, rows)
cursor.execute(insert_sql)
cursor.execute('commit')
i = i + 1
print(">>文件%s创建表完成" % csv_file_path)
load_csv('XXX.csv', '表名', '库名', 'UTF-8')基本思路就是逐行读取csv文件,第一行作为表头,各个字段拼接成一句create table;
后续表中的内容同理,每行逐字段读取,拼接成一句insert into;
每张需要参与计算的数据表都按照此函数导入到数据库中,就可以开始下一步计算了。
三、MySQL数据库按照考核标准计算结果,生成结果文件,再通过邮件发送结果文件
MySQL的计算基本上就是按照考核标准处理多张表中的数据,通过SQL语句实现,因为涉及到公司内部信息比较多,这里就不展示细节了;
可以展示一下实现的框架,通过cursor.execute("")来执行SQL语句,但是不能把分号”;“放在里面,目前没找到解决方法,因此每一句都是分开的:
print('>>开始生成结果表。。。')
## SQL1
cursor.execute("update XXX set `XXX`=replace(`XXX`, 'A', 'B')")
print('>>XXX,已完成')
## SQL2
cursor.execute("delete from XXX where `XXX` != 'XXXXX'")
cursor.execute("delete from XXX where `XXX` = '' and `XXX` = '' and `XXX` = ''")
print('>>XXX,已完成')下面是结果文件的生成,用xlwt导出结果表,还加入了一个按照内容调整每列宽度的功能,看起来方便些,最后断开数据库连接:
import xlwt
import copy
book = xlwt.Workbook()
def export_excel(table_name, sheet_name):
cursor.execute('select * from %s' % table_name) # 获取表
fields = [field[0] for field in cursor.description] # 获取所有字段名
all_data = cursor.fetchall() # 所有数据
# 写入excel
sheet = book.add_sheet('%s' % sheet_name)
col_num = [0 for x in range(0, len(fields))]
col_list = []
# 获取表头宽度,存入col_list
for col,field in enumerate(fields):
sheet.write(0,col,field)
col_num[col] = len(str(field).encode('gb18030'))
col_list.append(copy.copy(col_num))
row = 1
# 获取每行宽度,存入col_list
for data in all_data:
for col,field in enumerate(data):
sheet.write(row,col,field)
col_num[col] = len(str(field).encode('gb18030'))
col_list.append(copy.copy(col_num))
row += 1
# 函数:获取最适合的列宽
def get_max_col(max_list):
line_list = []
# i表示行,j代表列
for j in range(len(max_list[0])):
line_num = []
for i in range(len(max_list)):
line_num.append(max_list[i][j]) # 将每列的宽度存入line_num
line_list.append(max(line_num)) # 将每列最大宽度存入line_list
return line_list
# 调用函数get_max_col从col_list中获取最适合的列宽,并进行调整
col_max_num = get_max_col(col_list)
for i in range(0, len(col_max_num)):
sheet.col(i).width = 256 * (col_max_num[i] + 2)
print(">>结果表'%s'已导出为'%s'" % (table_name, sheet_name))
export_excel('数据库中表1', '导出表1')
export_excel('数据库中表2', '导出表2')
export_excel('数据库中表3', '导出表3')
book.save('XXX.xls')
print('>>结果文件已生成')
# 提交并断开数据库连接
cursor.execute('commit')
cursor.close()
db.close()
print('>>数据库连接已断开')最后通过邮件的方式发送检查结果:
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.header import Header
import smtplib
smtpserver = 'XXX' # SMTP服务器域名
username = 'XXX' # 登录用户名
password = 'XXX' # 登录密码
sender = 'XXX' # 发送者地址
receiver = ['XXX','XXX'] # 接收者地址
subject = '终端考核项检查结果' # 邮件标题
subject = Header(subject, 'utf-8').encode()
# 构建邮件对象
msg = MIMEMultipart('mixed')
msg['Subject'] = subject
msg['From'] = 'XXX'
msg['To'] = ";".join(receiver)
# 构造文字内容
text = "XXXXXX"
text_plain = MIMEText(text, 'plain', 'utf-8')
msg.attach(text_plain)
# 构造附件
sendfile = open('XXX.xls').read()
file_att = MIMEText(sendfile, 'base64', 'utf-8')
file_att["Content-Type"] = 'application/octet-stream'
file_att.add_header('Content-Disposition', 'attachment', filename = 'XXX.xls')
msg.attach(file_att)
# 发送邮件
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(username, password)
smtp.sendmail(sender, receiver, msg.as_string())
smtp.quit()
print('>>结果文件已通过邮件发送')整个工具写完以后,一共是1000+行。一开始运行需要40分钟,后来优化了平台导出表格的预处理,运行时间缩短到了10分钟;
不得不说Python做自动化的工具是真的很好用,只需要熟悉现成的模块,组合一下,就能实现很强大的功能。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:自动化终端考核检查系统的搭建过程 - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 