
在之前的博客中 ,您了解了名为Perceptron的单个人工神经元。在本神经网络教程中,我们将向前迈出一步,讨论称为多层感知器(人工神经网络)的感知器网络。
我们将在本神经网络教程中讨论以下主题:
- 单层感知器的局限性
- 什么是多层感知器(人工神经网络)?
- 人工神经网络如何工作?
- 用例
这篇关于神经网络教程的博客最后将包含一个用例。我们将使用 TensorFlow 实现该用例该用例。
现在,我将首先讨论单层感知器的局限性。
单层感知器的局限性
单层感知机有两个主要问题:
- 单层感知机无法对非线性可分数据点进行分类。
- 单层感知器无法解决涉及大量参数的复杂问题。
单层 Percpetrons 无法对非线性可分数据点进行分类
让我们通过异或门的例子来理解这一点。考虑下图:
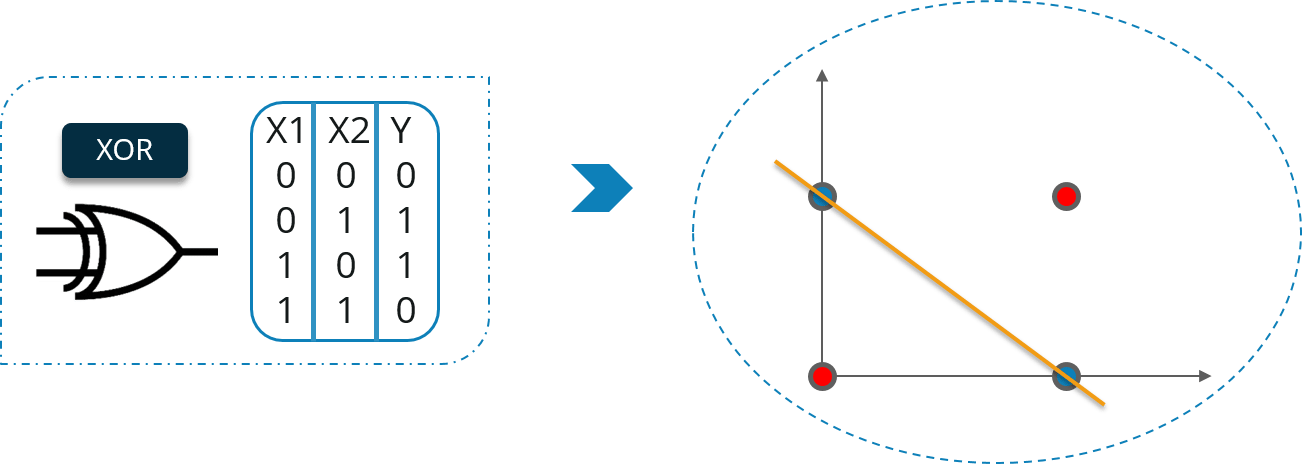
在这里,您不能用一条直线将高点和低点分开。但是,我们可以用两条直线将它分开。考虑下图:
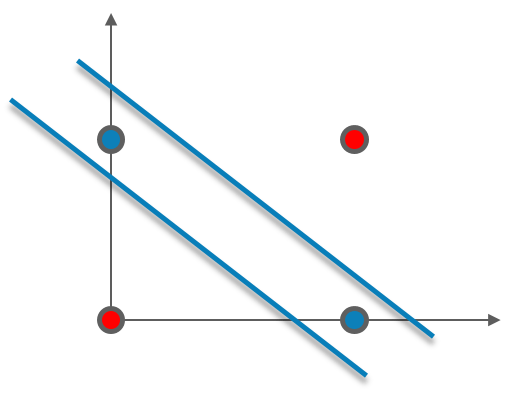
单层感知器无法解决涉及大量参数的复杂问题:
在这里,我也将举例说明。
作为一家电子商务公司,您注意到销售额下降。现在,您尝试组建一个营销团队来营销产品以增加销售额。
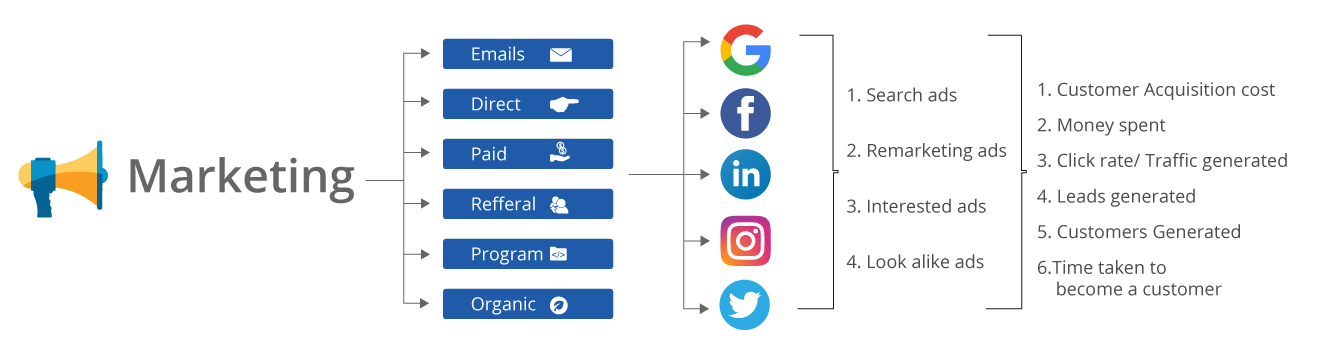
营销团队可以通过多种方式营销您的产品,例如:
- 谷歌广告
- 个人电子邮件
- 相关网站的销售广告
- 参考程序
- 博客等。. .
考虑到所有可用的因素和选项,营销团队必须决定一个策略来进行最佳和有效的营销,但这项任务对于人类来说太复杂了,无法分析,因为参数的数量非常多。这个问题必须使用深度学习来解决。考虑下图:
他们可以只使用一种方式来营销他们的产品,也可以使用多种方式。
每种方式都有不同的优点和缺点,他们将不得不关注各种因素和选择,例如:

将发生的销售数量将取决于不同的分类输入、它们的子类别和它们的参数。然而,仅通过一个神经元(感知器)不可能从如此多的输入及其子参数进行计算和计算。
这就是为什么要使用多个神经元来解决这个问题。考虑下图:
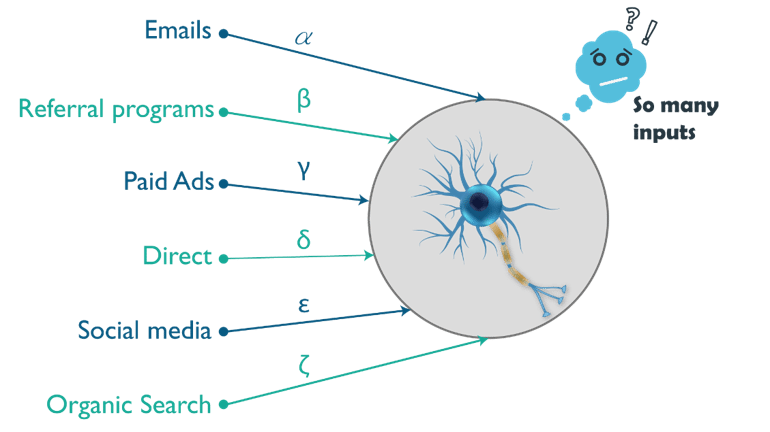
由于所有这些原因,单层感知器不能用于复杂的非线性问题。
接下来,在本神经网络教程中,我将重点介绍多层感知器 (MLP)。
什么是多层感知器?
如您所知,我们的大脑由数百万个神经元组成,因此神经网络实际上只是感知器的组合,以不同的方式连接并在不同的激活函数上运行。
考虑下图:
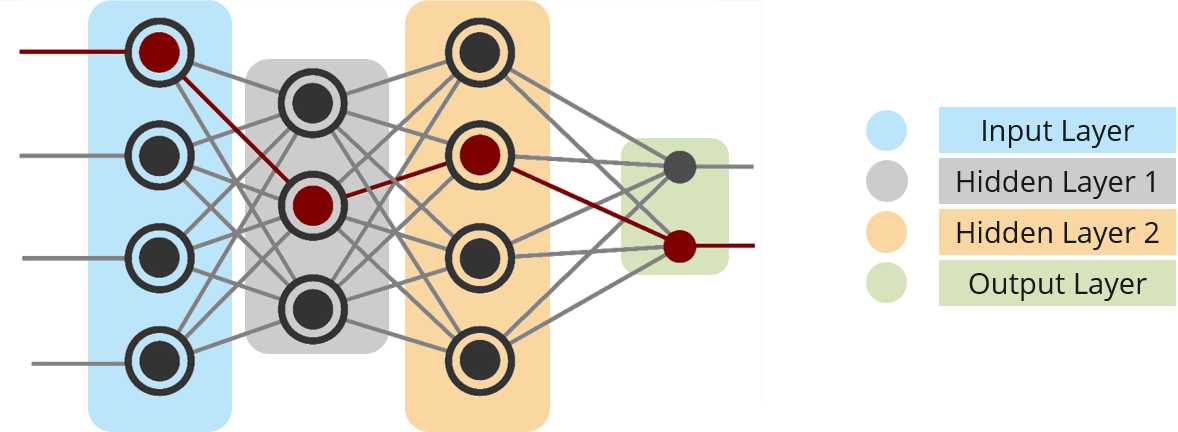
- 输入节点——输入节点将外部世界的信息提供给网络,统称为“输入层”。在任何输入节点中都不执行任何计算——它们只是将信息传递给隐藏节点。
- 隐藏节点——隐藏节点与外界没有直接联系(因此得名“隐藏”)。它们执行计算并将信息从输入节点传输到输出节点。隐藏节点的集合形成一个“隐藏层”。虽然网络只有一个输入层和一个输出层,但它可以有零个或多个隐藏层。多层感知器具有一个或多个隐藏层。
- 输出节点——输出节点统称为“输出层”,负责计算和将信息从网络传输到外界。
是的,你猜对了,我将举个例子来解释——人工神经网络是如何工作的。
假设我们有一支足球队Chelsea的数据。数据包含三列。最后一列显示切尔西是赢了还是输了。另外两列是关于上半场的进球领先和下半场的控球。控球率是球队控球时间的百分比。所以,如果我说一支球队在上半场(45 分钟)拥有 50% 的控球率,这意味着该球队在 45 分钟内有 22.5 分钟控球。
| 上半场进球领先 | 下半场控球 | 赢了还是输了 (1,0)? |
|---|---|---|
| 0 | 80% | 1个 |
| 0 | 35% | 0 |
| 1个 | 42% | 1个 |
| 2个 | 20% | 0 |
| -1 | 75% | 1个 |
最终结果列可以有两个值 1 或 0,表示切尔西是否赢得了比赛。例如,我们可以看到,如果上半场0球领先,而下半场切尔西控球率达到80%,那么切尔西就赢了比赛。
现在,假设我们要预测切尔西是否会赢得比赛,如果上半场的进球领先是 2,下半场的控球率为 32%。
这是一个二元分类问题,其中多层感知器可以从给定的示例(训练数据)中学习,并在给定新数据点的情况下做出明智的预测。我们将在下面看到多层感知器如何学习这种关系。
多层感知器学习的过程称为反向传播算法,我建议您阅读反向传播博客。
考虑下图:
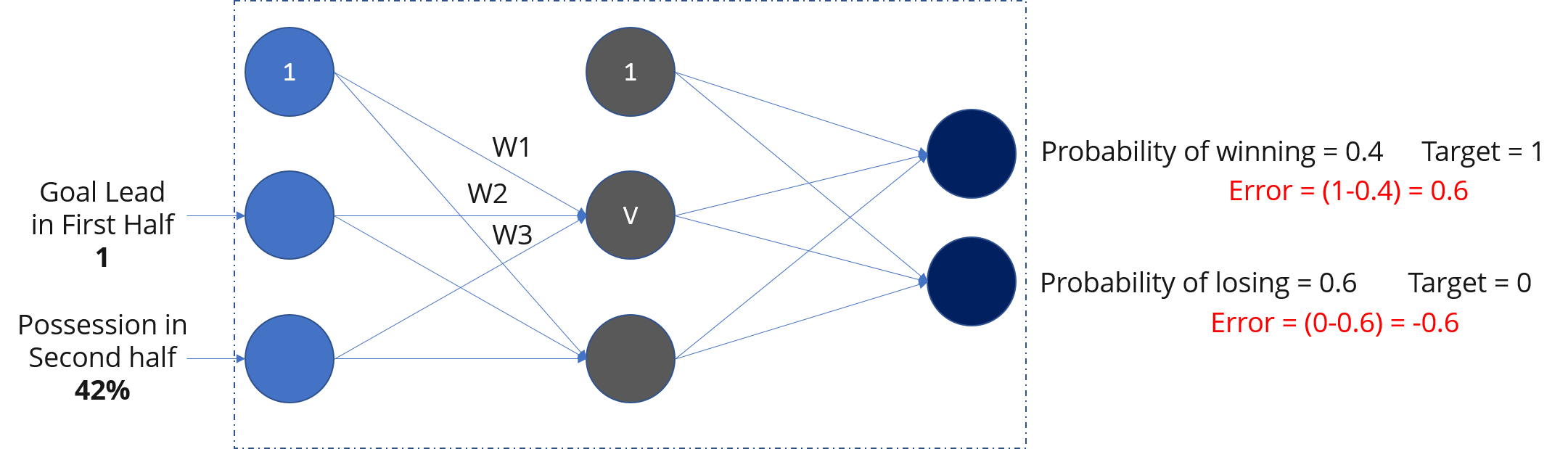
前向传播:
在这里,我们将向前传播,即计算输入的加权和并添加偏差。在输出层,我们将使用 softmax 函数来获得切尔西获胜或失败的概率。
如果您注意到图表,获胜概率为 0.4,失败概率为 0.6。但是,根据我们的数据,我们知道当上半场进球数领先为 1,下半场控球率为 42% 时,切尔西将获胜。我们的网络做出了错误的预测。
如果我们看到错误(将网络输出与目标进行比较),则为 0.6 和 -0.6。
反向传播和权重更新:
我建议您参考反向传播博客。
我们计算输出节点的总误差,并使用反向传播将这些误差传播回网络以计算 梯度。然后我们使用 梯度下降等优化方法 来“调整” 网络中的 所有权重,以减少输出层的错误。
让我来解释一下梯度下降优化器是如何工作的:
步骤-1:首先我们计算误差,考虑以下等式:
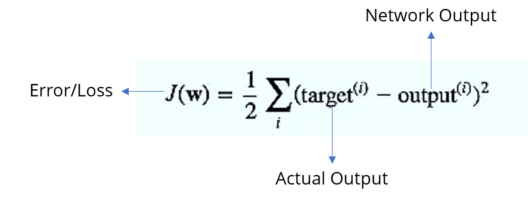
步骤–2:根据我们得到的误差,它会计算误差随权重变化的变化率。
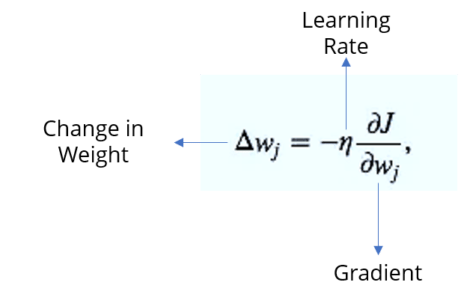
步骤–3:现在,根据这个重量变化,我们将计算新的重量值。
如果我们现在再次向网络输入相同的示例,网络应该比以前表现得更好,因为现在已经调整了权重以最小化预测误差。考虑下面的示例,如图所示,与之前的 [0.6, -0.4] 相比,输出节点的错误现在减少到 [0.2, -0.2]。这意味着我们的网络已经学会正确分类我们的第一个训练示例。
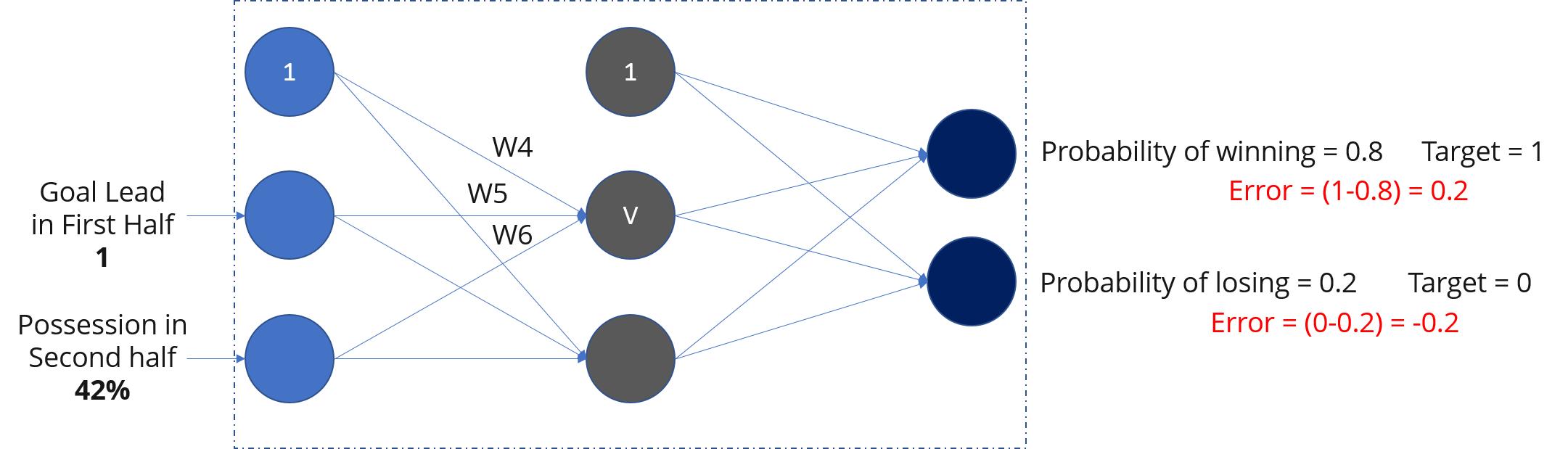
我们对数据集中的所有其他训练示例重复此过程。然后,据说我们的网络已经 学习了 这些例子。
现在,我可以将输入提供给我们的网络。如果我在上半场的进球数为 2,下半场的控球率为 32%,我们的网络将预测切尔西是否会赢得这场比赛。
现在,在本神经网络教程中,我们将获得动手实践的乐趣。我将使用 TensorFlow 为多层神经网络建模。
用例:
让我们看看我们的问题陈述:

现在,让我们看一下数据集,我们将使用它来训练我们的网络。
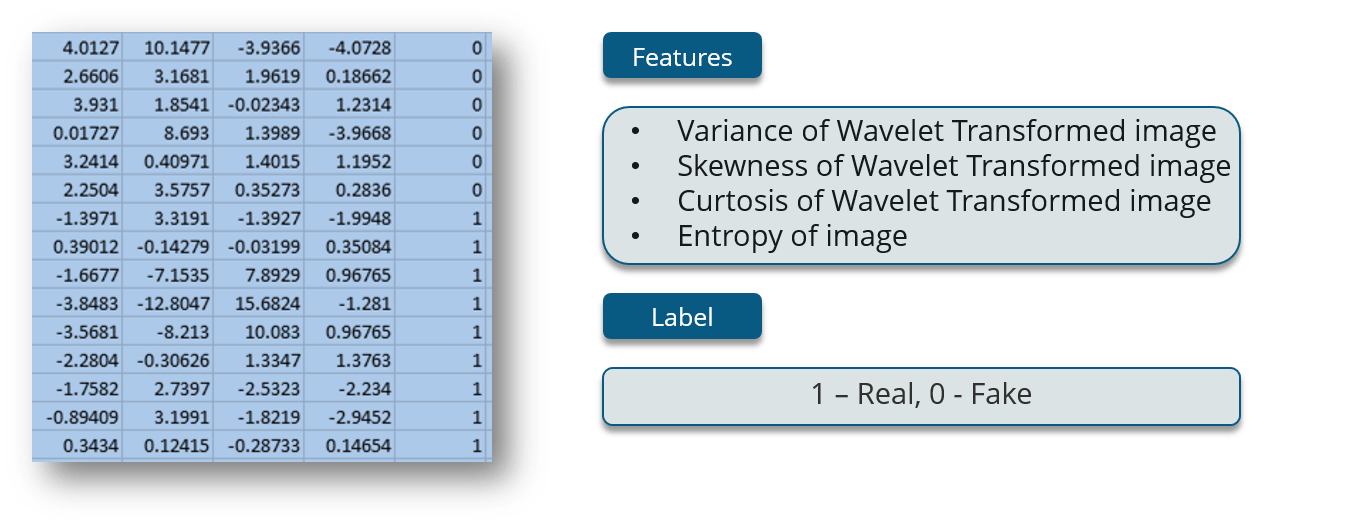
前四列是特征,最后一列是标签。
数据是从真品和伪造的类似钞票的样本的图像中提取的。最终图像有 400×400 像素。由于物镜和到被调查物体灰度的距离,获得了分辨率约为 660 dpi 的图片。小波变换工具用于从图像中提取特征。
为了实现这个用例,我们将使用下面的流程图:
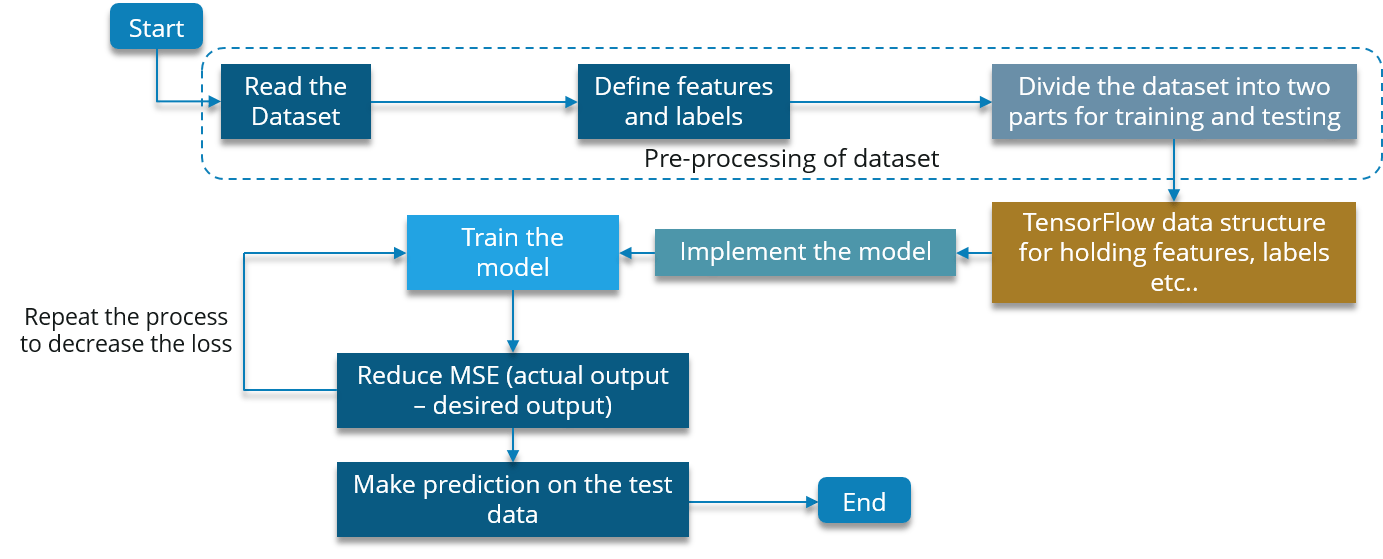
让我们现在执行它:
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# Reading the dataset
def read_dataset():
df = pd.read_csv("C:UsersSaurabhPycharmProjectsNeural Network Tutorialbanknote.csv")
# print(len(df.columns))
X = df[df.columns[0:4]].values
y = df[df.columns[4]]
# Encode the dependent variable
Y = one_hot_encode(y)
print(X.shape)
return (X, Y)
# Define the encoder function.
def one_hot_encode(labels):
n_labels = len(labels)
n_unique_labels = len(np.unique(labels))
one_hot_encode = np.zeros((n_labels, n_unique_labels))
one_hot_encode[np.arange(n_labels), labels] = 1
return one_hot_encode
# Read the dataset
X, Y = read_dataset()
# Shuffle the dataset to mix up the rows.
X, Y = shuffle(X, Y, random_state=1)
# Convert the dataset into train and test part
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.20, random_state=415)
# Inpect the shape of the training and testing.
print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
# Define the important parameters and variable to work with the tensors
learning_rate = 0.3
training_epochs = 100
cost_history = np.empty(shape=[1], dtype=float)
n_dim = X.shape[1]
print("n_dim", n_dim)
n_class = 2
model_path = "C:UsersSaurabhPycharmProjectsNeural Network TutorialBankNotes"
# Define the number of hidden layers and number of neurons for each layer
n_hidden_1 = 4
n_hidden_2 = 4
n_hidden_3 = 4
n_hidden_4 = 4
x = tf.placeholder(tf.float32, [None, n_dim])
W = tf.Variable(tf.zeros([n_dim, n_class]))
b = tf.Variable(tf.zeros([n_class]))
y_ = tf.placeholder(tf.float32, [None, n_class])
# Define the model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activationsd
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with sigmoid activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Hidden layer with sigmoid activation
layer_3 = tf.add(tf.matmul(layer_2, weights['h3']), biases['b3'])
layer_3 = tf.nn.relu(layer_3)
# Hidden layer with RELU activation
layer_4 = tf.add(tf.matmul(layer_3, weights['h4']), biases['b4'])
layer_4 = tf.nn.sigmoid(layer_4)
# Output layer with linear activation
out_layer = tf.matmul(layer_4, weights['out']) + biases['out']
return out_layer
# Define the weights and the biases for each layer
weights = {
'h1': tf.Variable(tf.truncated_normal([n_dim, n_hidden_1])),
'h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2])),
'h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3])),
'h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4])),
'out': tf.Variable(tf.truncated_normal([n_hidden_4, n_class]))
}
biases = {
'b1': tf.Variable(tf.truncated_normal([n_hidden_1])),
'b2': tf.Variable(tf.truncated_normal([n_hidden_2])),
'b3': tf.Variable(tf.truncated_normal([n_hidden_3])),
'b4': tf.Variable(tf.truncated_normal([n_hidden_4])),
'out': tf.Variable(tf.truncated_normal([n_class]))
}
# Initialize all the variables
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# Call your model defined
y = multilayer_perceptron(x, weights, biases)
# Define the cost function and optimizer
cost_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_function)
sess = tf.Session()
sess.run(init)
# Calculate the cost and the accuracy for each epoch
mse_history = []
accuracy_history = []
for epoch in range(training_epochs):
sess.run(training_step, feed_dict={x: train_x, y_: train_y})
cost = sess.run(cost_function, feed_dict={x: train_x, y_: train_y})
cost_history = np.append(cost_history, cost)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# print("Accuracy: ", (sess.run(accuracy, feed_dict={x: test_x, y_: test_y})))
pred_y = sess.run(y, feed_dict={x: test_x})
mse = tf.reduce_mean(tf.square(pred_y - test_y))
mse_ = sess.run(mse)
mse_history.append(mse_)
accuracy = (sess.run(accuracy, feed_dict={x: train_x, y_: train_y}))
accuracy_history.append(accuracy)
print('epoch : ', epoch, ' - ', 'cost: ', cost, " - MSE: ", mse_, "- Train Accuracy: ", accuracy)
save_path = saver.save(sess, model_path)
print("Model saved in file: %s" % save_path)
#Plot Accuracy Graph
plt.plot(accuracy_history)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
# Print the final accuracy
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Test Accuracy: ", (sess.run(accuracy, feed_dict={x: test_x, y_: test_y})))
# Print the final mean square er
pred_y = sess.run(y, feed_dict={x: test_x})
mse = tf.reduce_mean(tf.square(pred_y - test_y))
print("MSE: %.4f" % sess.run(mse))运行此代码后,您将获得以下输出:
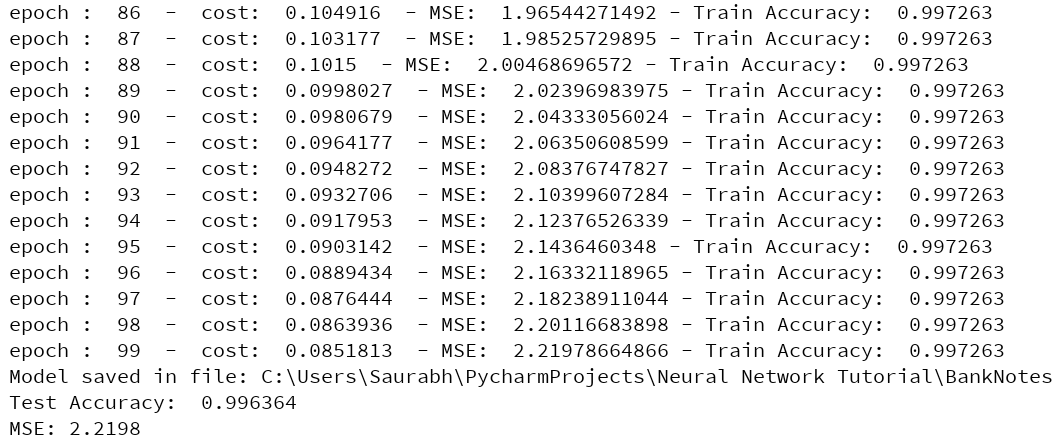
您可以注意到最终准确率为 99.6364%,均方误差为 2.2198。我们实际上可以通过增加 epoch 的数量来让它变得更好。
下面是 epoch vs accuracy 的图表:
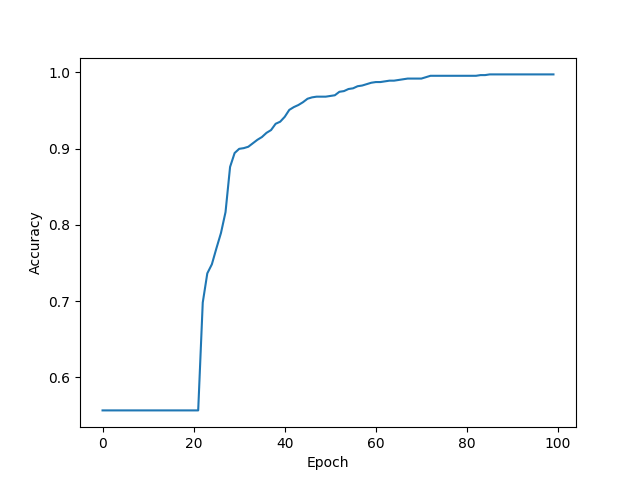
你可以看到,在每次迭代之后,准确度都在增加。
本站文章如无特殊说明,均为本站原创,如若转载,请注明出处:神经网络:多层感知器(附源码) - Python技术站
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 